

Пять проблем в управлении ИТ‑инфраструктурой, которые компании создают себе сами
ИТ редко ломается внезапно: даже при атаке корень проблемы обычно лежит в решениях, принятых внутри компании задолго до инцидента.
Внешнее давление сейчас значительно выросло. Санкции отрезали привычный софт и оборудование, найти сильного специалиста стало сложнее и дороже, требования регуляторов растут, а количество атак на российские компании увеличивается из года в год.
Атаковать компанию стало дешевле и проще, а фишинговую атаку можно окупить с первого успешного входа. Но внешние угрозы бьют сильнее именно туда, где внутри уже что‑то не так.
Рассказываю, как такие ошибки накапливаются и к чему это приводит на практике.
Подрядчику отдали не только задачи, но и контроль
Привлекать подрядчика — нормально. Проблема начинается, когда вместе с задачами ему уходят доступы, документация и понимание того, как вообще устроена инфраструктура.
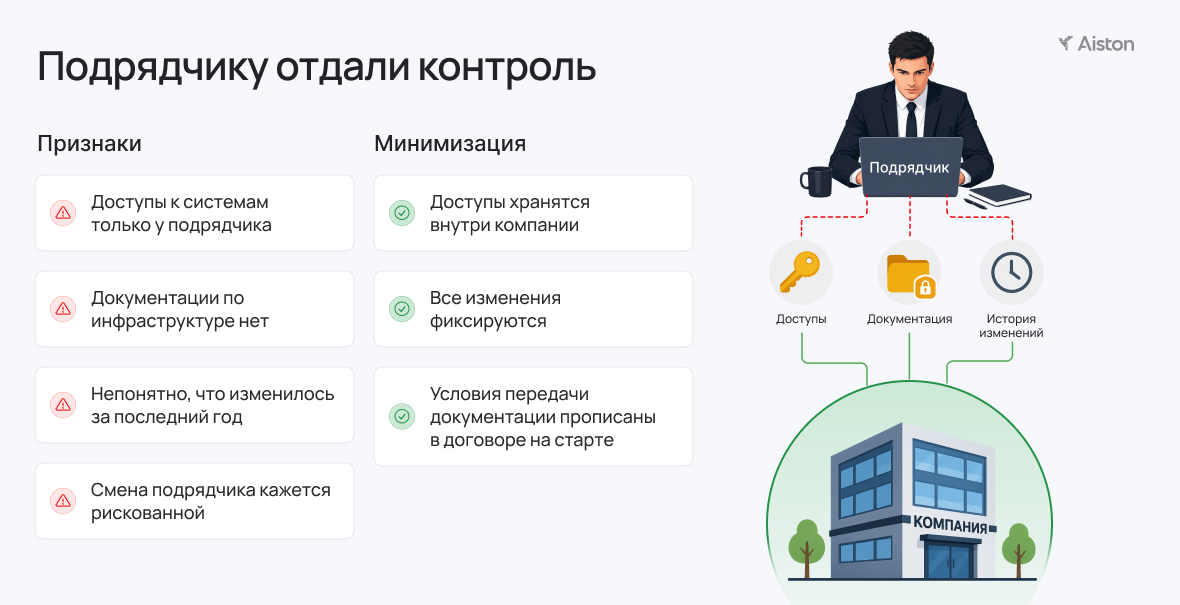
Простой кейс. Один из наших клиентов — сервисная компания на 2000 человек — привлёк подрядчика для точечных задач: настроить серверы, почту, 1С. Подрядчик справился, и постепенно ему начали отдавать всё больше.
Когда компания решила его поменять, выяснилось, что у неё нет ни документации, ни карты сервисов, ни доступов. Подрядчик при этом начал активно препятствовать переходу. Смена в итоге обошлась в несколько миллионов рублей — только прямые затраты, без учёта потерь от простоев.
Избежать зависимости можно ещё на старте, когда вы только начинаете работать с ИТ‑подрядчиком. Доступы должны оставаться внутри компании, изменения — фиксироваться, а условия передачи документации и прав доступа — сразу прописываться в договоре.


- Налоговая служба утвердила форму документа о предстоящей поставке для СПОТ
- Количество получающих господдержку самозанятых сократилось на треть за год
- Количество налоговых проверок в России снижается, но сумма доначислений растет
- Аналитики подсчитали возможные убытки бизнеса из‑за «фальшивых» самозанятых
- М.Видео запустил регистрацию партнерских ПВЗ по всей России
- Россияне чаще выбирают формат ИП для запуска бизнеса
Чёрный ящик как неуправляемый прибор
Чёрный ящик в самолёте — намеренно защищённый прибор. Его содержимое понимают только профильные специалисты: он нужен для разбора полётов после катастрофы.

В ИТ‑инфраструктуре компании чёрные ящики появляются сами собой. Это системы, которые годами никто не трогает, потому что они и так работают.
Парадокс в том, что именно такие системы становятся главной точкой риска. Примерно 1/3 инцидентов происходит через уязвимости, которые давно исправлены в новых версиях, но обновление никто не ставил.
Мы регулярно видим системы, которые не обновлялись 3–5 лет. В одном из наших в Aiston проектов уязвимость в Microsoft Exchange Server, закрытая ещё в 2021 году, позволила получить доступ к внутренней сети за несколько часов. Компания не работала два дня, хотя устранить уязвимость можно было за один рабочий день.
Чтобы избежать этого, раз в полгода проверяйте версии ключевых систем и сравнивайте с актуальными. Обновляйте системы — риск не обновлять всегда выше, чем риск обновления.

Инфраструктура без внимания
Часто инфраструктура в среднем бизнесе растёт стихийно: руководители больше заинтересованы в продажах, чем в поддержке и обеспечении ИТ.
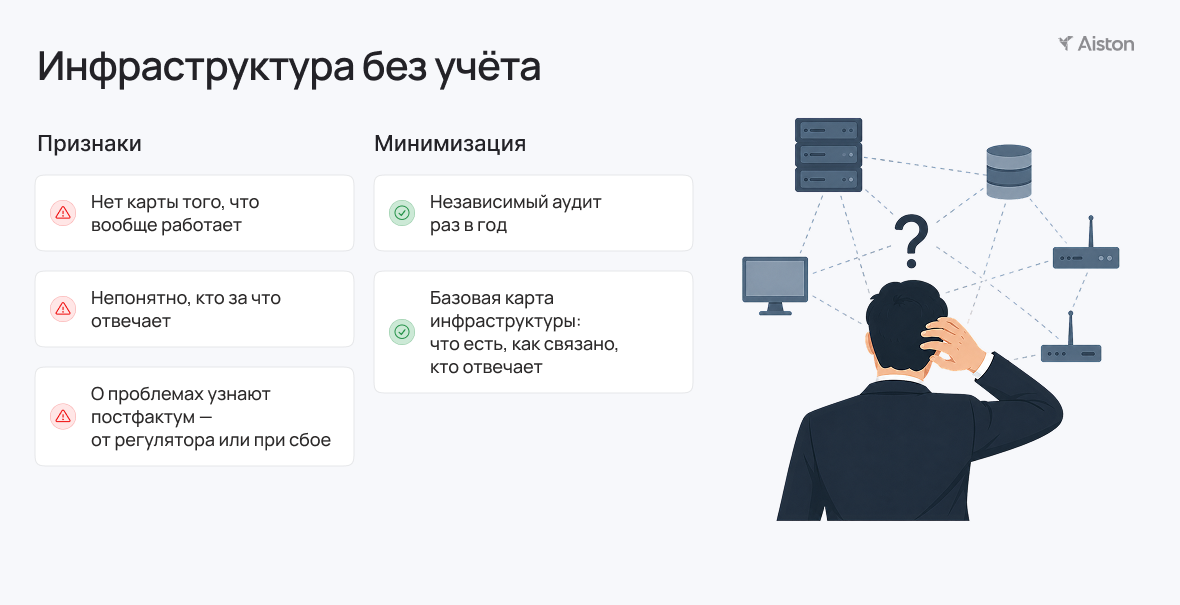
Оборудование, сервисы и ИТ‑подрядчики появляются по мере задач, но никто не ведёт учёт того, что накапливается. Импортозамещение добавляет слой неразберихи: часть систем — старые западные, часть — новые российские, часть — в облаке.
В итоге из‑за отсутствия понимания никто не может этим управлять. О несоответствии требованиям компании обычно узнают, когда уже платят штраф.
Соберите базовую карту инфраструктуры: что есть, как связано, кто за что отвечает. Лучше, чтобы это был не столько технический документ, сколько инструмент для руководителя.

Без ответственных
Когда инцидент случается, у компании обычно есть и подрядчик, и администратор, и служба безопасности. Но если заранее не прописано, кто реагирует первым — в момент сбоя все звонят друг другу и выясняют это на ходу.
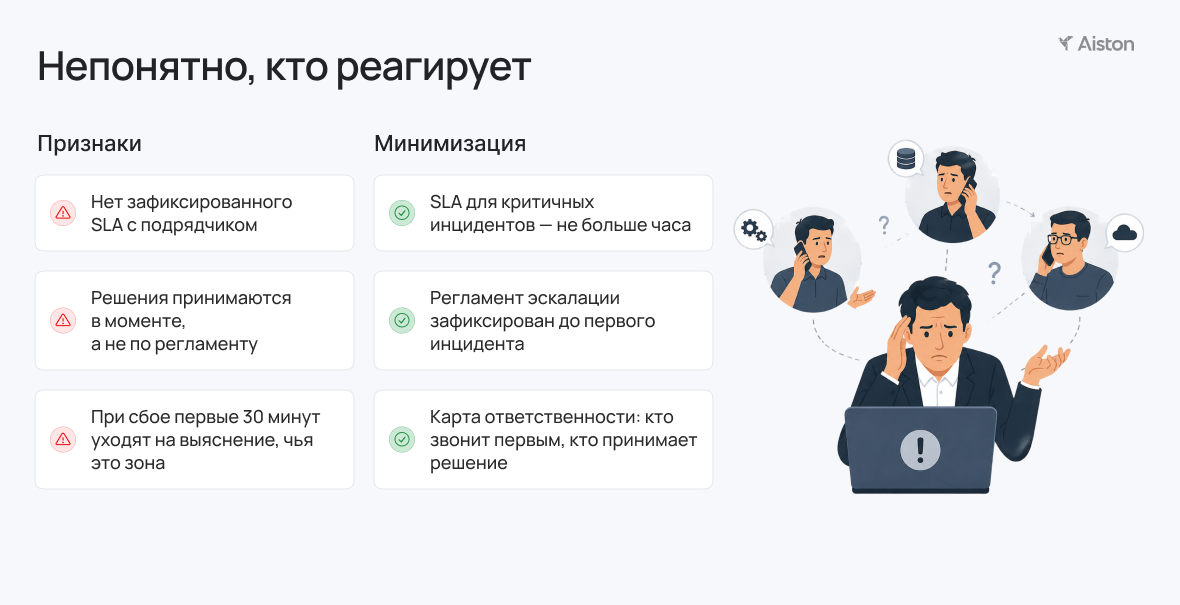
Показательный случай с компанией с заводами по всей России из нашей практики.
Ночью во Владивостоке встали отгрузки, потому что упала 1С. В Москве об этом узнают только утром. Руководство звонит подрядчику, пишет администратору и выясняет, что до сих пор никто не понимает, где именно проблема и кто за неё отвечает прямо сейчас.
Проблему решили. Но за несколько часов простоя компания потеряла на срыве отгрузок больше, чем стоило бы нормально прописать договор на старте.
Кибератаки работают ещё быстрее: среднее время от проникновения до нанесения ущерба — 48 минут. В ситуации, когда непонятно, кто отвечает за инцидент, эти минуты превращаются в часы потерь.
Для этого нужны три вещи, которые фиксируются заранее: карта ответственности с тем, кто за что отвечает в момент сбоя, SLA для разных типов инцидентов и простой регламент — кто звонит первым и кто принимает решение об эскалации.
Один за всех
Один сисадмин на компанию — распространённая история. Со временем он действительно знает всё: какой кабель куда идёт, почему 1С настроена именно так, какой пароль от какой системы. Годами всё держится на нём.

Такая ситуация опасна тем, что в случае, если сотрудник заболел, ушёл в отпуск или уволился, то годы накопленных знаний об инфраструктуре уходят вместе с ним.
Найти замену сейчас занимает вдвое больше времени, чем три года назад: рынок перегрет, специалистов перекупают крупные компании. Полгода без нормальной ИТ‑поддержки — это не страшилка, это сценарий, который мы видели не раз.
Вести ИТ‑реестр (что есть и как настроено), регламентировать ключевые операции и хранить все доступы в корпоративном хранилище, а не в одной голове.
Что важно вынести
Бизнес не может контролировать внешние факторы: кибератаки могут расти, кадровый рынок и регуляторика будут меняться.
Но компания с управляемым ИТ переживает те же самые потрясения принципиально легче. Минимум, который должен быть в любой компании:
- ИТ‑реестр: что есть, как настроено, кто отвечает.
- Базовый мониторинг: дашборд с ключевыми метриками.
- Карта ответственности: кто звонит первым при сбое.
- Документация на основные операции: перезапуск, восстановление бэкапа.
- Все доступы в корпоративном хранилище, не в одной голове.
- SLA с подрядчиком, прописанный до первого инцидента.
Если смотреть на этот список и понимать, что половины нет — можно разбираться самостоятельно, а можно начать с обследования ИТ‑инфраструктуры. Это занимает несколько дней, стоит недорого и даёт представление о том, что есть. Дальше уже понятно, что делать и в каком порядке.










