
Первые 4 часа после взлома: пошаговый план реагирования и восстановления
Кибератаки на финансовые организации уже стали постоянным операционным риском. По данным Банка России, в 2025 году были выявлены сотни инцидентов операционной надежности, DDoS‑атак и фишинговых сайтов, а отдельной проблемой стали атаки через подрядчиков. Поэтому первые часы после взлома нельзя тратить на хаотичные обсуждения: именно в это время компания может ограничить распространение атаки, сохранить доказательства и не допустить длительного простоя.
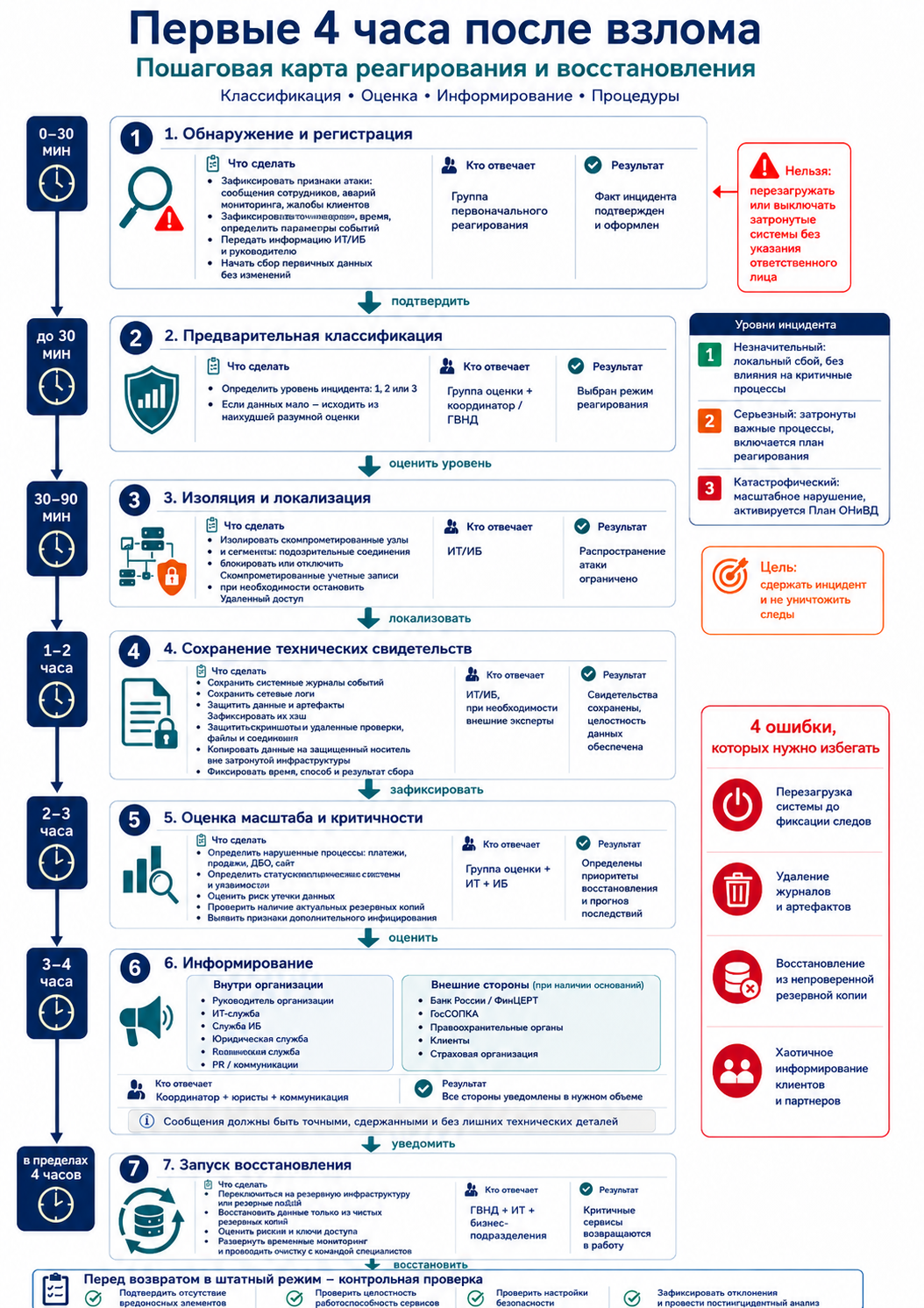
Ниже — практический план действий на первые четыре часа. Его можно использовать как основу для внутренней инструкции, чек‑листа для оперативного штаба или сценария учебной тренировки.
Почему первые 4 часа после взлома решают исход инцидента
В первые часы после взлома организация еще может повлиять на развитие атаки. Если быстро подтвердить инцидент, изолировать затронутые системы и сохранить логи, ущерб обычно можно ограничить. Если же действовать без плана, есть риск потерять следы атаки, случайно уничтожить доказательства или восстановить сервисы из зараженной резервной копии.
Главная цель этого периода — не «починить все любой ценой», а вернуть ситуацию под управление. Для этого нужно одновременно решать четыре задачи: остановить распространение инцидента, понять масштаб, сохранить технические свидетельства и подготовить безопасное восстановление.
В первые часы лучше исходить из наихудшей разумной оценки. Если масштаб атаки пока неясен, инцидент стоит считать серьезным до тех пор, пока команда не докажет обратное.

- Т-Банк и НИУ ВШЭ договорились о поддержке студенческого предпринимательства
- До 1 июля ИП нужно уплатить дополнительные страховые взносы
- Анализ Т‑Бизнес секретов: зумеры стали активнее покупать товары для рыбалки
- Приложение Telega прекращает работу с 1 июля
- Транспортные компании повышают тарифы из‑за перебоев с топливом
- Налоговая служба сообщила о резком росте дробления бизнеса
Какие нормативные требования учитывать финансовым организациям
Для финансовых организаций реагирование на киберинцидент связано не только с информационной безопасностью, но и с операционной надежностью. Поэтому инцидент нужно рассматривать как событие, которое может нарушить работу сервисов, технологических процессов и объектов информационной инфраструктуры.
В качестве базовой логики можно использовать ГОСТ Р 57580.4‑2022. В нем важен процесс 3 — «Выявление, регистрация, реагирование на инциденты и восстановление после их реализации». Он задает последовательность действий: выявить инцидент, зарегистрировать признаки, отреагировать на угрозу, восстановить процессы и затем разобрать причины и последствия.
Дополнительно нужно учитывать требования Положения Банка России № 850‑П об операционной надежности и Положения Банка России № 242‑П о внутреннем контроле и непрерывности деятельности.
Практический смысл этих требований следующий: у организации заранее должен быть план действий на случай нестандартных и чрезвычайных ситуаций, а не набор решений, которые придумываются уже во время кризиса. Также важно заранее определить срок восстановления, который не будет превышать допустимое время простоя или приводить к ухудшению соответствующего технологического процесса.

Кто должен участвовать в реагировании
Даже хороший технический план не сработает, если в первые минуты после взлома непонятно, кто принимает решения. Поэтому в организации заранее определяют ответственного координатора и рабочие группы. Координатор не выполняет все действия сам, а удерживает общий контур управления: собирает команды, расставляет приоритеты, согласует решения и докладывает руководству.
Обычно в реагировании участвуют такие группы:
- группа первоначального реагирования — подтверждает факт инцидента и отделяет атаку от обычного технического сбоя;
- руппа оценки — определяет масштаб, затронутые системы, критичность и возможные последствия;
- группа восстановления непрерывности — координирует восстановление процессов и работу оперативного штаба;
- группа ИТ‑инфраструктуры — изолирует узлы, блокирует подозрительные соединения, меняет учетные данные и восстанавливает сервисы;
- юридическая группа — оценивает регуляторные последствия, помогает с уведомлениями и оформлением документов;
- группа коммуникаций — готовит сообщения для клиентов, партнеров, СМИ и внутренних аудиторий.
Такое разделение помогает избежать двух типичных проблем: когда все ждут решения одного человека или, наоборот, когда разные подразделения одновременно делают несогласованные действия.


Что делать в первые 30 минут, через 1‑2 часа и в конце четвертого часа
Шаг 1. Обнаружить и зарегистрировать инцидент: 0–30 минут. Первый шаг — подтвердить, что организация действительно столкнулась с киберинцидентом, а не с обычным сбоем. Сигнал может прийти из систем мониторинга, от сотрудников, от клиентов, от подрядчика или из‑за аномалий в работе сервиса.
Что сделать в первые минуты:
- зафиксировать источник сигнала: система мониторинга, сообщение сотрудника, жалоба клиента, аварийное уведомление;
- записать время обнаружения, затронутый сервис и первые признаки атаки;
- передать информацию ИТ‑службе, службе информационной безопасности и ответственному координатору;
- начать сбор первичных данных без изменения затронутых систем;
- отдельно отметить действия, которые уже были выполнены до подключения группы реагирования.
Нельзя: перезагружать или выключать затронутые системы без согласования с ответственным лицом. Так можно уничтожить важные следы инцидента: временные файлы, сетевые соединения, процессы в памяти и часть журналов.
Шаг 2. Предварительно классифицировать инцидент: до 30 минут. После регистрации инцидент нужно предварительно классифицировать. Это помогает понять, какие ресурсы подключать и какой режим реагирования запускать. В первые часы информации обычно мало, поэтому классификация может быть временной. Но даже временная оценка лучше, чем отсутствие решения.
На практике в первые часы многие инциденты безопаснее считать серьезными, пока не доказано обратное. Если есть признаки утечки данных, нарушения переводов, шифрования файлов или недоступности клиентских сервисов, уровень критичности нужно повысить.
Шаг 3. Изолировать и локализовать атаку: 30–90 минут. Когда факт инцидента подтвержден, команда должна ограничить распространение атаки. Это делает ИТ‑инфраструктура совместно со службой информационной безопасности. Важно действовать аккуратно: при локализации нельзя уничтожить доказательства и создать еще больший простой.
Что можно сделать на этом этапе:
- изолировать скомпрометированные узлы и сегменты сети;
- заблокировать подозрительные соединения;
- временно отключить или ограничить скомпрометированные учетные записи;
- приостановить удаленный доступ, если через него может продолжаться атака;
- ввести временные ограничения на операции, если есть риск мошеннических переводов;
- зафиксировать все действия: кто, когда и почему принял решение.
Цель локализации — сдержать инцидент и не уничтожить следы. Поэтому любые радикальные действия (например, полное выключение систем или массовое удаление файлов) должны согласовываться с координатором реагирования.
Шаг 4. Сохранить технические свидетельства: 1–2 часа. После локализации нужно сохранить данные, по которым позже можно восстановить картину атаки. Эти материалы понадобятся для технического анализа, внутреннего расследования, оценки правовых последствий и, при необходимости, для обращения к регулятору или правоохранительным органам.
Что стоит собрать и сохранить:
- системные журналы событий затронутых объектов;
- логи сетевого взаимодействия;
- сведения антивирусного и другого защитного программного обеспечения;
- данные о подозрительных процессах, файлах и сетевых соединениях;
- скриншоты, выгрузки из систем мониторинга и артефакты удаленного доступа;
- время, способ и результат сбора каждого свидетельства.
Собранные данные нужно копировать на защищенный носитель вне затронутой инфраструктуры. Важно сохранить целостность материалов: кто собирал данные, каким способом, где они хранятся и были ли они изменены после копирования.
Шаг 5. Оценить масштаб и критичность: 2–3 часа. К этому моменту у команды уже должны быть первичные данные. Теперь нужно понять, какие системы затронуты, какие процессы нарушены и насколько быстро их можно вернуть в работу.
В первую очередь оценивают процессы, которые напрямую влияют на клиентов и финансовые операции: прием платежей, переводы, дистанционное обслуживание, бухгалтерский учет и другие критичные функции. Одновременно проверяют объекты инфраструктуры: серверы, базы данных, сетевое оборудование, рабочие станции, учетные записи и интеграции с подрядчиками.
Также необходимо исключить риск утечки защищаемой информации. Если есть признаки доступа к персональным данным, сведениям о счетах или финансовых операциях, режим реагирования должен быть жестче. Также важно понять, есть ли актуальные резервные копии и можно ли им доверять.
По итогам оценки команда фиксирует окончательный или уточненный уровень критичности и определяет, какие процессы нужно восстанавливать первыми.
Шаг 6. Проинформировать ответственных лиц и внешние стороны: 3–4 часа. Информирование должно начаться после первичного понимания масштаба инцидента. Внутри организации уведомляют руководство, ИТ‑службу, службу информационной безопасности, юридическое подразделение, финансовый блок и коммуникационную команду. Это нужно, чтобы решения принимались согласованно, а каждое подразделение понимало свою роль.
Внешнее информирование проводят только при наличии правовых, регуляторных или договорных оснований. Сообщения должны быть точными, сдержанными и достаточными для понимания ситуации. Не стоит раскрывать лишние технические детали: ими могут воспользоваться злоумышленники.
Сообщение для клиентов должно показывать, что организация контролирует ситуацию и уже принимает меры. Обычно достаточно указать факт технического или киберинцидента, кратко описать влияние на услуги и обозначить порядок восстановления.
Шаг 7. Запустить восстановление: в пределах 4 часов. Восстановление начинается не тогда, когда «все понятно», а тогда, когда известны минимально необходимые условия безопасного возврата критичных сервисов. Команда должна понимать уровень критичности, затронутые системы, доступность резервных копий и приоритеты восстановления.
Порядок восстановления обычно выглядит так:
- Стабилизировать инфраструктуру: изолировать затронутые объекты, заблокировать подозрительные соединения и ограничить скомпрометированные учетные записи.
- Проверить резервные копии: убедиться, что они созданы до момента компрометации и не содержат вредоносных элементов.
- Восстановить критичные сервисы: при необходимости переключиться на резервную инфраструктуру, альтернативные каналы обслуживания или резервный центр обработки данных.
- Обновить учетные данные: сменить пароли, ключи доступа и другие секреты, связанные с затронутыми системами.
- Проверить восстановленные объекты: подтвердить работоспособность сервисов, отсутствие вредоносных элементов и корректность настроек безопасности.
- Зафиксировать результат: описать, что восстановлено, какие ограничения остаются и какие действия нужны дальше.
Возврат в штатный режим допускается только после контрольной проверки. Если восстановить сервис быстро можно только с нарушением процедуры, такое решение должно быть отдельно согласовано с руководителем группы восстановления непрерывности.
Каких ошибок нельзя допускать при восстановлении
В первые часы после взлома многие ошибки возникают из‑за желания быстрее «погасить пожар». Но некоторые быстрые решения ухудшают ситуацию и усложняют расследование.
Что сделать заранее, чтобы план сработал
План реагирования полезен только тогда, когда он подготовлен до инцидента. В момент взлома уже поздно распределять роли, искать ответственных и спорить о том, кто может принимать решения.
Чтобы первые четыре часа прошли управляемо, организации стоит заранее:
- утвердить внутренние правила реагирования и восстановления;
- назначить ответственного координатора и состав рабочих групп;
- описать уровни критичности инцидентов и критерии перехода между ними;
- подготовить порядок сбора технических свидетельств;
- проверить резервные копии и сценарии переключения на резервную инфраструктуру;
- подготовить шаблоны уведомлений для руководства, регулятора, клиентов и партнеров;
- регулярно проводить учения, сценарный анализ и тестирование процедур.
Системная подготовка снижает вероятность хаотичных действий, помогает сохранить непрерывность критичных процессов и упрощает выполнение требований в области информационной безопасности и операционной надежности.
Итог
Первые четыре часа после взлома — это время, когда организация должна не просто реагировать технически, а управлять инцидентом. Сначала нужно подтвердить и зарегистрировать факт атаки. Затем — классифицировать инцидент, изолировать затронутые системы, сохранить доказательства, оценить масштаб, уведомить нужные стороны и запустить безопасное восстановление.
Главный принцип: скорость важна, но она не должна уничтожать следы атаки или запускать повторное заражение. Хороший план заранее определяет роли, порядок решений и критерии восстановления.
'%20fill='none'/%3e%3cpath%20fill='%23ffdd2d'%20d='%20M%20104.72%200.00%20L%20112.15%200.00%20Q%20106.48%207.74%20100.12%2014.37%20C%2091.89%2022.97%2081.81%2029.47%2071.49%2035.26%20Q%2061.95%2040.62%2051.54%2043.77%20C%2044.52%2045.90%2036.57%2046.85%2028.99%2047.67%20Q%2027.29%2047.86%2025.66%2047.43%20Q%2025.42%2047.37%2025.35%2047.61%20L%2025.26%2047.91%20A%200.45%200.44%2017.2%200%200%2025.56%2048.47%20C%2028.12%2049.22%2035.16%2050.72%2036.90%2052.43%20Q%2038.92%2054.39%2036.21%2054.48%20Q%2033.33%2054.58%2029.50%2053.79%20Q%2019.39%2051.71%209.25%2049.83%20C%207.27%2049.47%205.11%2048.66%203.49%2047.83%20Q%200.61%2046.36%203.73%2045.50%20Q%204.67%2045.25%206.46%2044.38%20Q%2010.76%2042.31%2026.76%2034.35%20C%2030.51%2032.48%2037.88%2029.46%2041.00%2033.59%20A%200.92%200.91%20-35.3%200%201%2040.77%2034.91%20L%2029.13%2042.42%20Q%2027.57%2043.42%2029.42%2043.22%20C%2053.59%2040.61%2073.35%2028.09%2091.94%2013.14%20Q%2099.20%207.31%20104.72%200.00%20Z'%20/%3e%3c/svg%3e)










