

От сырых данных к рабочей модели: что решает датасет
Машинное обучение работает только тогда, когда совпадают несколько условий: грамотные алгоритмы, продуманная архитектура и качественные данные. Датасеты в этой связке играют ключевую роль — именно они позволяют моделям учиться на реальных примерах и приносить бизнесу ощутимую пользу.
В статье расскажем, что такое датасеты, зачем они нужны бизнесу (и какому), а также как понять, что вам пора обращаться к экспертам.
Что такое датасеты
В машинном обучении датасет — это структурированный набор данных, который используется для обучения, проверки и тестирования моделей. Обычно это таблица, где каждая строка — отдельный объект, а каждая колонка — характеристика или атрибут этого объекта. К элементам могут быть прикреплены файлы разных форматов: изображения, аудио, видео, текстовые документы — всё, что важно для задачи.
Примеры структуры датасета:
- Кодинг: таблица с примерами кода: строка = один кодовый пример, колонки = язык, тип задачи, сложность, результат тестов.
- Текстовые данные: таблица с отзывами клиентов: строка = один отзыв, колонки = оценка, категория, тональность, ключевые слова.
Сырые данные vs размеченные данные. Сырые данные — это необработанная информация, которую сложно использовать напрямую. Например, стопка оцифрованных квитанций, набор фото без описаний, логи сервера без структуры. Размеченные данные — это уже готовый к употреблению материал: к каждому элементу добавлена ценная информация, которая делает данные полезными для AI.
Как это может выглядеть:
- сырые данные — это список ингредиентов, а размеченные — это рецепт, где расписано, как их применять, чтобы получить готовое блюдо, кратно увеличив ценность исходных сырых материалов;
- сырые данные — это стопка оцифрованных квитанций, а датасет — это бухгалтерская таблица, где видны все нужные значения для каждой квитанции: дата, сумма к оплате, задолженность.

Почему важны качество и структуризация данных. Качество исходных данных для разработки ML‑систем сильно влияет на итоговое решение. Но даже самые точные измерения не принесут пользы, если они системно не обработаны.
В повседневной жизни мы тоже встречаемся с этим принципом. Например, если вы фиксируете тренировки — время, нагрузку, количество повторений, ощущения после занятия — и делаете это системно, можно понять, какие подходы работают лучше, и планировать следующие тренировки эффективнее. Аналогично с личным бюджетом: просто записывать расходы недостаточно. Если всё структурировано по категориям, датам и суммам, легко увидеть, куда уходят деньги, выявить паттерны и принять более разумные финансовые решения.
На бытовом уровне это и есть датасет: набор сведений, аккуратно зафиксированных и структурированных, чтобы их можно было анализировать и использовать для прогнозов или решений. В ML разметка выполняет ту же функцию — превращает сырые данные в форму, на которой модели учатся и работают корректно.

Рассылка: как вести бизнес в России
Пять полезных писем пришлем сразу после подписки. В них — бизнес‑идеи, готовые промпты для нейросетей, советы, как выбрать налоговый режим и получать пассивный доход
Виды датасетов и их значение для бизнеса
Датасеты бывают очень разными в зависимости от формата данных и сферы применения. Вот лишь несколько примеров.
Текстовые данные — это отзывы, обращения, сообщения в соцсетях. Они помогают выявлять ключевые тренды, классифицировать обращения и прогнозировать потребности клиентов. AI, обученный на таких данных, может автоматически выделять частые вопросы или проблемные темы, освобождая сотрудников от рутинной работы и повышая точность обработки информации.
Изображения применяются в e‑commerce, медицине, промышленности и т.д. Фотографии товаров помогают создавать визуальный поиск и рекомендации, медицинские снимки — обучать модели для диагностики, а на производстве компьютерное зрение позволяет определять качество изделий. Например, анализ яркости огня при производстве стали помогает моделям точно оценивать качество продукта и снижать брак.
Аудио- и видеоданные — это записи звонков в колл‑центрах и с видеокамер, следящих за безопасностью. AI на основе этих данных распознаёт речь, автоматически выявляет инциденты или оценивает работу операторов. Это сокращает ошибки и повышает эффективность процессов.
Сложный тип данных: маркетинговые и клиентские (User behavior data) — клики, переходы, содержимое корзины, просмотры страниц, обращения в техподдержку. Они помогают персонализировать предложения, прогнозировать спрос и увеличивать конверсию. Например, модель подбирает товары, которые с высокой вероятностью купит пользователь, что напрямую влияет на CTR и выручку. А чат‑бот, обученный на данных обращений клиентов, может отвечать быстрее и точнее человека, снижая среднее время решения вопросов и повышая удовлетворённость пользователей (NPS).
Качественные датасеты нужны на двух этапах цикла разработки продукта.
Первая задача возникает на этапе, когда модель ещё не внедрена, и бизнес пока работает «вручную». Например, в службе поддержки сотрудники отвечают клиентам самостоятельно, или на сайте подбор товаров ведётся только за счёт фильтров. Чтобы перейти к автоматизации, необходимо обучить модель на данных, которые отражают реальные сценарии. Такой датасет становится основой для обучения и позволяет показать первые результаты — своего рода MVP, после которого бизнес принимает решение автоматизировать процесс.
Вторая задача возникает после запуска AI‑сервиса. На этом этапе датасеты нужны для повышения качества. Если модель подбирает нерелевантные товары (вместо стиральной машины рекомендует кофемашину), обновление и расширение датасета помогает повысить точность и скорость. В результате улучшаются ключевые метрики: конверсия в покупку, удовлетворённость клиентов, выручка.
Таким образом, датасеты обеспечивают как стартовую проверку эффективности AI‑решения, так и его постоянное улучшение.
Этапы работы с данными
Прежде чем ставить задачу на создание датасета для модели, важно понять два момента: какой результат мы хотим получить и какими должны быть данные. Например, если вы хотите, чтобы модель консультировала клиентов по продукту, важно заранее определить, какие вопросы она должна уметь отвечать и как выглядит информация, на которой она будет учиться. Без этого легко потратить ресурсы впустую или получить модель, которая решает задачу некачественно.
Чтобы избежать подобных проблем, стоит разобраться, какие шаги включает работа с датасетами — от постановки целей до структуры, разметки и хранения данных — и как на каждом этапе контролировать качество, чтобы получить набор, пригодный для обучения.
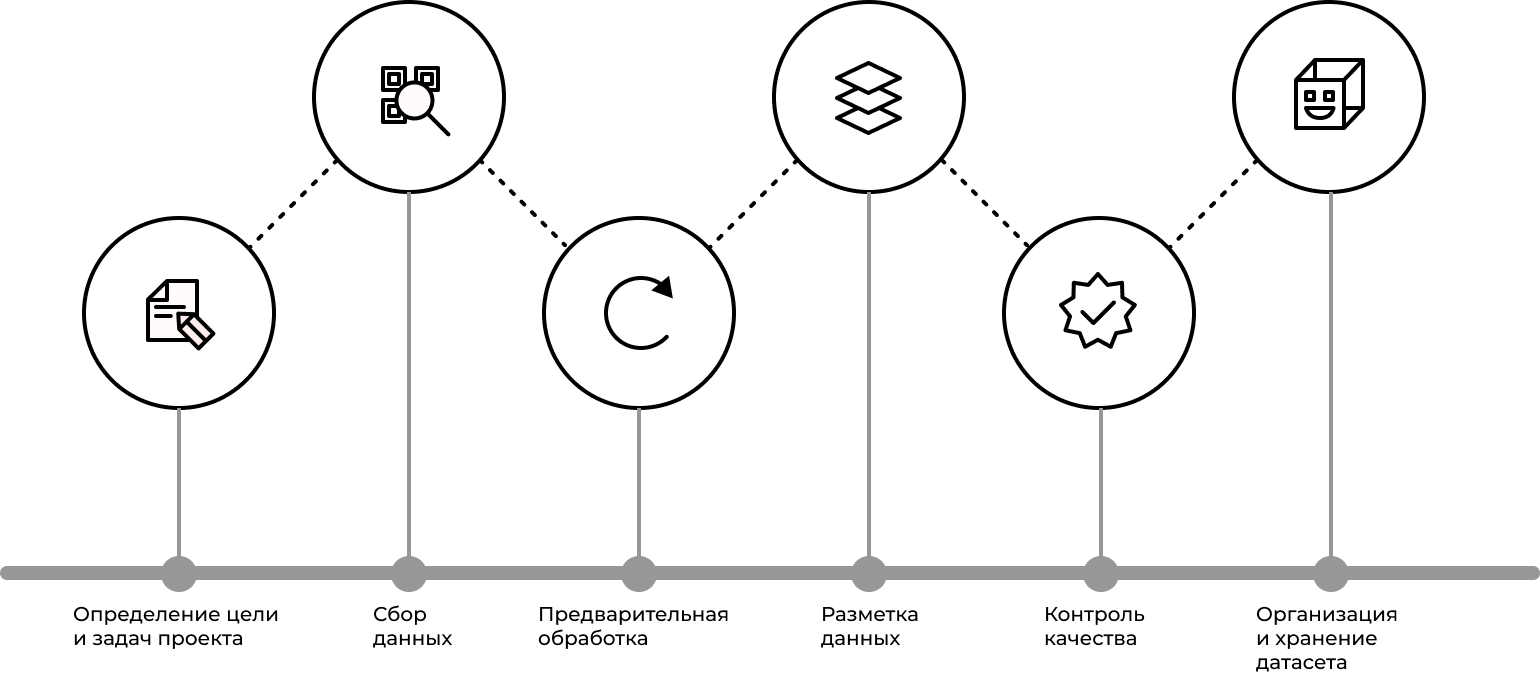
Этап № 1. Ставим задачу. Какую проблему будет решать модель и какие результаты ожидаются? Ответ на этот вопрос поможет правильно выбрать тип данных и объем датасета. В зависимости от цели, датасет может быть предназначен для разных типов задач:
- Классификация — присвоение входным данным определенной категории. Например, фильтрация спам‑писем в почтовой системе или сортировка заявок клиентов по приоритету.
- Регрессия — предсказание числового значения. Например, оценка стоимости недвижимости по параметрам квартиры или прогноз спроса на товар.
- Сегментация изображений — выделение отдельных объектов на изображении. Например, определение границ органов на медицинских снимках или поиск дефектов на производственной линии.
- Обработка естественного языка (NLP) — анализ текста. Например, извлечение названий компаний из юридических документов, классификация отзывов по тональности или саммаризация текстов.
Этап № 2. Формулируем требования. Теперь нам нужно понять, какие данные действительно нужны для решения задачи. При определении требований учитывают:
- тип данных: изображения, видео, текст, числа, аудио — в зависимости от задачи; например, для рекомендаций в e‑commerce нужны клики, покупки и фотографии товаров; для промышленного контроля — видео с камер и данные сенсоров и т.д.;
- необходимые признаки: характеристики данных, которые модель будет использовать; например, для прогнозирования цен на недвижимость важны площадь, местоположение, год постройки;
- объем данных: количество примеров, необходимых для обучения; маленький датасет подходит для простых задач и первичного тестирования, а большой (>100 000 записей) — для глубокого обучения сложных нейросетей.
Этап № 3. Выбираем источники. Требования определили, теперь смотрим, откуда будем брать данные:
- Из внешних источников. Это открытые базы (Kaggle, UCI), государственные отчеты, аналитические исследования, данные из соцсетей. Они позволяют быстро собрать информацию, но требуют проверки на актуальность, качество и легальность использования.
- Внутренние источники — данные, которые собирает сама компания: логи сайта, транзакции, поведение пользователей, данные IoT‑устройств. Такие датасеты точнее отражают бизнес‑процессы, но требуют правильной инфраструктуры для хранения и обработки.
- Организуем сбор данных. Когда нужных данных нет, их собирают с помощью камер, сенсоров, анкет, аудио- или видеозаписей. Этот подход дает полный контроль над качеством, но требует дополнительных ресурсов.
Обычно речь идет о двух стратегиях: сборе своими силами или через подрядчиков. Сбор своими усилиями — это часто путь компаний, у которых есть доступ к необходимой инфраструктуре. Например, производитель автомобилей может использовать камеры, установленные в своих тестовых машинах, или завод — собственные сенсоры на конвейере.
Преимущество этого подхода в том, что компания полностью контролирует процесс и гарантирует соответствие данных внутренним требованиям. Но есть и минус: высокие затраты времени и ресурсов, нужно не только собирать данные, но и хранить их, поддерживать оборудование, обучать персонал.
«В случае со сбором через подрядчиков компания формулирует техническое задание и передает его организации. Подрядчик самостоятельно организует процесс: например, ищет участников для записи аудио, устанавливает камеры в нужных локациях или собирает изображения по заданным параметрам. Такой подход экономит ресурсы и позволяет получить данные быстрее. Но здесь важна точность формулировок в ТЗ: если они будут слишком общими, результат может не совпасть с ожиданиями, поэтому важно внимательно отнестись к его составлению».

Алексей Корнилов
Moderation Group Manager at Data LightКупим готовые датасеты. Иногда целесообразно приобрести уже подготовленные датасеты, они могут ускорить работу и сэкономить ресурсы, особенно для сложных или редких задач. При этом важно убедиться, что данные подходят под вашу задачу и права на их использование соблюдены.
У заказчика может возникнуть резонный вопрос: «Зачем тогда покупать, если всё равно придется перепроверять?» На рынке действительно можно столкнуться с сомнительными предложениями: данные могут формально подходить под задачу, но при этом использоваться без соблюдения авторских или лицензионных прав. Поэтому ключевой момент здесь — выбор надежного поставщика или подрядчика, которому можно доверять. Такой партнер не только поставляет данные, но и гарантирует их качество и корректность с правовой точки зрения.
Выбор источника определяется задачей, объемом данных и сроками проекта. Например, для проверки алгоритма обработки текста можно использовать открытые отзывы, а для промышленной линии — внутренние сенсорные данные и фотографии дефектов.
Этап № 4. Собираем и очищаем данные. Когда готовых данных нет и не нашлось подходящих источников, их собирают самостоятельно. Для этого используют камеры и сенсоры (например, чтобы отслеживать движение людей в торговом зале), микрофоны (для записи речи), анкеты и опросы. Такой путь даёт полный контроль над качеством, но требует много времени и ресурсов.
Сырые данные нужно очистить: в них встречаются пропуски, ошибки, дубликаты и откровенный мусор. Чтобы подготовить материалы к обучению модели, нужно:
- убрать дубликаты;
- заполнить пропуски — средним значением, медианой или с помощью предсказания;
- привести данные к единому масштабу;
- отсеять аномалии, которые искажают результат.
Пример из практики: заказчик поставил на первый взгляд простую задачу: нужно собрать через крауд‑платформу фото и видео, где люди произносят цифры. Нужны были записи, сделанные представителями разных этнических групп — 200 наборов данных от участников из Африки и 100 наборов данных из Индии.
Казалось, пару недель — и всё готово. На деле же мы погрузились в хаос: часть участников присылала ролики, снятые в темноте, кто‑то отправлял TikTok вместо задания, а инструкции читали единицы.
В итоге пришлось перестроить процесс: записали видеопримеры, упростили инструкции, перевели их на актуальные языки, добавили автоматическую генерацию последовательностей и повысили финансовую мотивацию участников. Финальные данные прошли многоуровневую проверку — от автоматических фильтров до ручной оценки командой.
В итоге из хаоса получился аккуратный датасет, а проект завершился вовремя. Этот опыт показал: даже самые простые задачи в сборе данных легко превращаются в головоломку, если не продумать процесс до мелочей.
Этап № 5. Валидация. Когда мы говорим о подготовке датасета, очистка — это только первый шаг, когда убирают дубликаты, пропуски и другие очевидные ошибки. После этого наступает этап разметки (аннотации): данные получают метки, чтобы с ними можно было работать дальше.
Затем проводят валидацию, и здесь речь идёт не о проверке работы модели, а именно о контроле качества данных. Обычно формируется валидационная выборка, по которой можно оценить средний уровень качества аннотации — какой процент ошибок встречается. Если показатель оказывается слишком высоким для конкретного проекта, проводят повторную разметку, дополнительную проверку или корректируют процесс.
«Контроль качества данных — это не формальная проверка. Универсальных метрик не существует: error rate полезен, но в каждом проекте критерии должны подбираться под специфику данных и цели бизнеса. Точно так же и выборка требует математического подхода: важно учитывать случайность, равномерность и репрезентативность. Наконец, реальная экспертиза формируется из довольно узкой специализации. Лучшие валидаторы глубоко понимают нюансы конкретных направлений, будь то компьютерное зрение (CV) или речевые модели».
Алексей Корнилов
Moderation Group Manager at Data LightЭтап № 6. Что происходит с датасетом дальше. Когда данные уже размечены и проверены, их используют для обучения модели. Но и здесь важно правильно распределить материал: датасет не применяют целиком, иначе модель просто заучит примеры и не сможет работать с новыми ситуациями. Поэтому данные делят на три части.
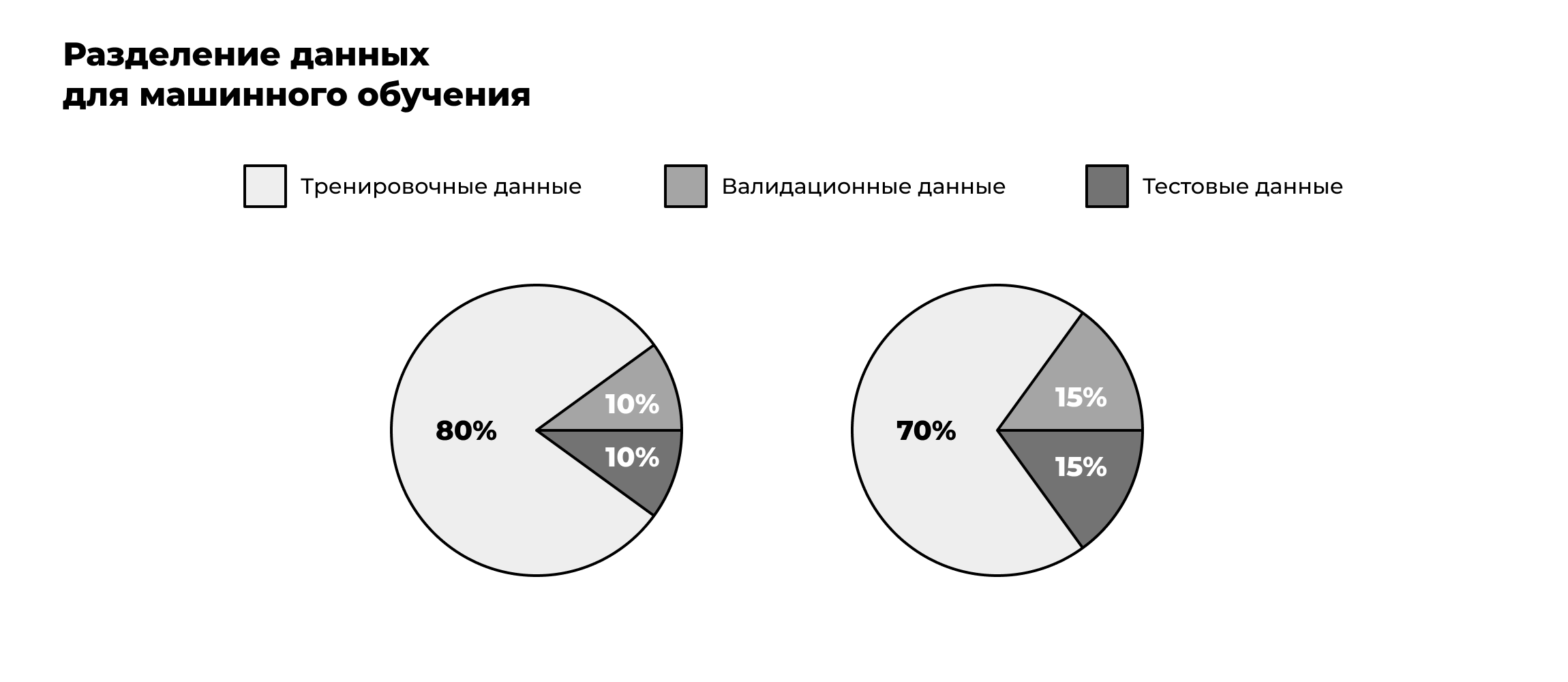
Большая часть — 70–80% — уходит на обучение. Это основа: на этих данных модель ищет закономерности и учится предсказывать результат.
Следующие 10–15% составляют валидационную выборку. Её можно представить как черновую проверку: модель уже что‑то умеет, и мы смотрим, насколько хорошо она справляется с новыми примерами. Если результат слабый, меняем настройки — например, глубину нейросети или скорость обучения.
Оставшиеся 10–15% — тестовая выборка. Это финальный экзамен, и трогать эти данные раньше времени нельзя. Именно на них проверяют, как модель поведёт себя в боевых условиях.
Такое разделение помогает честно оценить результат и защититься от переобучения — ситуации, когда алгоритм идеально угадывает старые примеры, но сыпется на новых.
Этап № 7. Оформляем документацию. Даже идеально собранный датасет бесполезен, если в нём невозможно разобраться. Поэтому важна не только структура папок и единые форматы файлов, но и документация. Она отвечает на главный вопрос: что это за данные и как с ними работать.
Хорошая документация описывает, из чего состоит датасет, в каком формате лежат файлы и зачем нужны вспомогательные таблицы. В ней указывают, откуда брались данные и какие инструменты использовали при сборе. Если в датасете есть разметка, нужно пояснить, как её делали: вручную, с помощью краудсорсинга или полуавтоматически.
Отдельный пункт — ограничения. Например, бывают наборы, которые можно применять только в исследовательских целях или в определённой отрасли. Без этого пояснения легко нарваться на юридические проблемы.
Документация и метаданные превращают набор файлов в понятный инструмент: с ними команда быстрее разберется в структуре и сможет использовать данные без лишних вопросов.
Как собрать данные: плюсы и минусы разных подходов
С целями разобрались, схему подготовки датасета уяснили. Теперь давайте подумаем, где мы возьмем данные: соберем сами, привлечем краудсорсинг или купим готовые. У каждого способа есть свои достоинства и недостатки.
Инхаус. Если решаете организовывать сбор своими силами, значит:
- нужен специалист, который будет заниматься сбором, очисткой и разметкой данных;
- если задача большая, придётся нанимать команду аннотаторов, обучать их, контролировать качество;
- задача может оказаться разовой, а нанятую команду потом придется загружать работой;
- контроль качества может оказаться слабым, если нет постоянного отдела, который этим занимается.
Плюс — полный контроль над процессом. Минус — долго и дорого.
Краудсорсинг. Этим занимаются крупные платформы и легко можно запустить проект на большой объём данных, но есть свои нюансы:
- Мошенничество. Много пользователей загружают «мусорные» данные или делают работу формально, не вникая в инструкции.
- Качество разметки часто непредсказуемо. Чтобы получить нормальный результат, может понадобиться повторная проверка, что в итоге удорожает проект.
- Специфичных экспертов найти трудно, и узкоспециализированные задачи сложнее выполнить.
Плюс — дешево и быстро для простых задач. Минус — нестабильное качество, риск мошенничества и сложности с редкими компетенциями.
Несмотря на постоянную борьбу с мошенничеством на крауд‑площадках, оно по‑прежнему встречается довольно часто. Например, один пользователь может выполнять задания с нескольких аккаунтов или повторно на разных платформах. Формально это не нарушает правила, но приводит к появлению дубликатов.
«Чтобы избежать таких ситуаций, мы применяем нейросетевые решения по аналогии с технологиями распознавания лиц (face recognition): они извлекают эмбеддинги и помогают находить дублирующиеся данные между площадками».
Алексей Корнилов
Moderation Group Manager at Data LightИменно поэтому внешние компании нередко оказываются эффективнее в сборе данных. У них уже выстроены процессы, есть опыт взаимодействия с различными крауд‑площадками и понимание, где оптимально собирать конкретные типы данных (аудио, видео, изображения или текст). Такие компании знают особенности аудитории, этническое распределение и географию участников, умеют оптимизировать стоимость заданий и сроки сбора, чтобы получить необходимый объём данных без перерасхода бюджета.
Покупка готовых датасетов. Готовые размеченные датасеты могут быть выгодным решением: это обычно дешевле и быстрее, чем собирать данные самостоятельно. Особенно это актуально для компаний, которым важно быстро запустить проект или протестировать гипотезу.
Однако есть ряд особенностей, на которые стоит обратить внимание:
- Совпадение с задачей. Формат, структура или тип объектов в готовом датасете могут не полностью соответствовать вашим требованиям. Иногда данные требуют дополнительной калибровки и интеграции с уже имеющимися.
- Стоимость. В большинстве случаев покупка действительно обходится дешевле, чем полный цикл сбора и разметки. Но в специализированных областях — например, в медицине — такие датасеты могут стоить дорого.
- Качество и риски. Заказчик обычно видит лишь примеры (samples) данных до покупки, поэтому есть риск столкнуться с некачественным или неоригинальным материалом. Чтобы минимизировать риски, важно тщательно выбирать поставщика и работать с проверенными подрядчиками.
Таким образом, покупка готовых датасетов — это способ сэкономить время и ресурсы, но успех во многом зависит от качества и надежности поставщика.
Почему внешняя компания часто выигрывает. Профессиональный подрядчик решает многие проблемы одновременно:
- собирает и обучает команду нужного размера и квалификации;
- гарантирует предсказуемое качество и контроль данных;
- позволяет сэкономить внутренние ресурсы и время.
Именно поэтому, когда задача сложная или данные нужны быстро и качественно, а инхаус и краудсорсинг вызывают сомнения — разумно обратиться к проверенному партнёру.
«Проблема краудсорсинговых платформ заключается в том, что исполнители сильно меньше контролируются. Конечно, крупные компании делают всякие антифрод‑механизмы и другие ухищрения, чтобы препятствовать фроду и мошенничеству, но все равно есть доля непроконтролированных исполнителей и датапоинтов. Она значительно больше, чем в датасетах команд, которые являются самостоятельной компанией, в которых исполнители работают в штате».

Александр Кирилов
BDM at DoubletappАутсорсинг сбора и разметки данных: как выбрать подходящего подрядчика
Почему подрядчик на аутсорсе — это проще, быстрее и надёжнее?
Скорость и масштаб. Иногда нужно промаркировать сотни тысяч объектов. Например, робот‑уборщик должен отличать мусорные баки от тротуара и машин. Если на это выделить пять сотрудников, процесс растянется на месяцы. Аутсорсинговая компания собирает команду нужного размера за считаные дни.
Качество и экспертиза. Для сложных задач, как анализ рентгеновских снимков или поиск мельчайших дефектов на производственных линиях, важны точность и опыт специалистов. Внутри компании найти таких людей не всегда возможно. Профессиональный подрядчик привлекает экспертов и сразу обучает их нужной методике.
Экономия ресурсов. Своих сотрудников нужно нанять, обучить, обеспечить инфраструктурой и загрузить задачами. Аутсорс позволяет решить проект в рамках бюджета, без скрытых расходов и простоев.
Временные проекты. Иногда разметка нужна на короткий период. Например, компания тестирует алгоритм для распознавания зимних дорог: снег, лужи, ямы. Нанимать штат на пару недель — невыгодно. Аутсорс решает задачу быстро и без лишних затрат.
На что обратить внимание при выборе партнера:
- Опыт и инструменты. Компания должна иметь навыки именно в вашей области и подходящие технологии для работы с нужными данными.
- Безопасность. Данные часто конфиденциальны: медицинские снимки, корпоративные материалы. NDA и защита информации — обязательны.
- Контроль качества. Важна система валидации: проверка части данных, ручной контроль, статистика по командам и обучение валидаторов.
Как начать:
- Пилотный проект: начинайте с маленького объёма, чтобы оценить навыки подрядчика, инструменты и реальный уровень качества.
- Контроль прогресса и точности: следите за тем, как поставщик выполняет работу, проверяйте точность и бенчмаркуйте результаты на открытых или внутренних данных.
- Минимизация ошибок и затрат: хороший подрядчик позволяет быстро исправлять ошибки и повторно аннотировать данные без хаоса. Бюджет остается предсказуемым.
«Мы растим валидаторов так, чтобы каждый прокачивал свою тему и становился по‑настоящему сильным в ней. Но чтобы глаз не замыливался и работа не шла по конвейеру, мы специально оставляем 10–20% времени на проекты чуть в стороне от основной линии — те, что интересны самому человеку. Это позволяет сохранить интерес, а в итоге мы получаем команду, которая не просто закрывает задачи, а делает это стабильно и на высоком уровне».
Алексей Корнилов
Moderation Group Manager at Data LightПодытожим: как подойти к проекту по разметке данных в бизнесе
Работа с датасетами начинается не с таблиц и файлов, а с формулировки цели. Нужно честно ответить: что именно мы хотим улучшить или автоматизировать. Это может быть сокращение времени обработки документов, рост точности чат‑бота или оптимизация рекомендаций. Без этой точки отсчёта легко собрать горы данных, которые не принесут пользы.
Дальше — выбор типа данных. Тексты, изображения, аудио, специализированные документы — у каждого формата своя специфика и риски.
Следующий шаг — решить, кто будет делать проект: внутренняя команда или подрядчик. На первый взгляд может показаться, что дешевле собрать студентов или поручить всё LLM. Но здесь работает эффект «синтетичности»: модель размечает данные в своём стиле, и эта неестественность потом переходит в целевую систему. В результате качество падает.
Поэтому важно думать о контроле качества. Это не разовая проверка, а система: выборочные проверки на каждом этапе, метрики на входе и выходе, фиксация ошибок. Если перепроверять только малую часть данных или экономить на времени аннотатора — качество сразу просядет.
И наконец, финальный вопрос — окупается ли проект. Здесь важно смотреть не только на стоимость разметки. Есть несколько метрик, которые помогают считать ROI:
Экономия времени. Если раньше сотрудники тратили часы на ручную проверку документов или сообщений, а теперь это делает модель — вы выигрываете десятки человеко‑часов в месяц.
Скорость вывода продукта на рынок. Чем быстрее появляется качественный датасет, тем раньше вы запускаете новую функцию или сервис.
Качество сервиса. Это можно замерять по точности модели (precision, recall), снижению числа ошибок, улучшению NPS или уровню удовлетворённости клиентов.
Прямой рост продаж. Например, если рекомендательная система благодаря новым данным предлагает более релевантные товары, средний чек и конверсия растут.
Снижение издержек. Хороший датасет уменьшает количество ручных операций, снижает нагрузку на саппорт или сокращает расходы на доработку продукта.
По сути, датасет — это актив, который работает на вас каждый день. Он окупается не в момент завершения разметки, а улучшает бизнес‑процессы и продукты на протяжении месяцев и лет.
Нужны ли вашему бизнесу датасеты?
Мы уже разобрали, что такое датасеты, как они создаются и почему качество играет ключевую роль. Осталось задать главный вопрос: кому они действительно нужны и стоит ли задуматься о них вашему бизнесу?
Датасеты нужны не только гигантам IT‑рынка. С такими игроками мы тоже работаем, но круг заказчиков постоянно расширяется.
«Раньше бы я ответил, что датасеты в больших и внятных количествах нужны крупным производителям ML‑решений. Назовем chatGPT, назовем DeepSeek и подобное. Но сейчас же все начинают вайбкодить жестко и производить очень много нишевых ML‑решений. И я вижу, что, возможно, у большого количества маленьких компаний будет потребность в небольших датасетах.
И нам здесь как бизнесу нужно будет думать над готовыми решениями, готовыми датасетами, закрывающими определенный круг задач небольших бизнесов. Просто для маленьких бизнесов нужно будет показывать большую ценность, чтобы обучение на датасете значительно улучшало качество модели и, соответственно, бизнес‑метрики».
Александр Кирилов
BDM at DoubletappЕсли говорить о малых языковых моделях, то сегодня крупные технологические компании, такие как Amazon или Google, обучают свои системы на колоссальных объёмах данных и вычислительных мощностях, недоступных среднему бизнесу.
Однако не всегда требуется масштабное обучение, чтобы получить реальную ценность от искусственного интеллекта. Малые языковые модели дешевле, работают быстрее и могут быть дообучены под конкретные задачи компании (например, для оптимизации бизнес‑процессов или увеличения прибыли). Для их обучения тоже нужны данные и разметка, но в гораздо меньших объёмах, чем для моделей уровня ChatGPT. Поэтому даже компании среднего и малого размера уже могут ощутимо выиграть от внедрения таких решений.
Так что небольшие команды и стартапы также приходят к необходимости использовать качественные датасеты. Например, разработчики приложений с компьютерным зрением могут встроить в продукт модель, которая распознаёт открытые двери автомобиля, номера машин или оценивает грейд коллекционных карточек; компании, работающие с носимыми устройствами, обучают модели фиксировать действия вокруг пользователя и т. д.
У таких команд путь обычно один и тот же: они начинают с дешёвых автоматизированных решений, чтобы протестировать гипотезу. Если проект подтверждает бизнес‑ценность — растёт выручка, появляется лояльная аудитория — возникает запрос на более качественный датасет. И это уже не затраты ради эксперимента, а инвестиция, которая даёт стабильный прирост метрик.
Таким образом, рынок датасетов нельзя считать нишей только для крупных компаний. Да, именно лидеры формируют спрос и задают темп, но потенциал в сегменте небольших компаний огромный. Им нужны не терабайты данных, а точные, выверенные выборки, которые позволяют быстрее выйти на рынок и предложить клиенту реально качественный сервис.














