

AI‑поиск и оптимизация контента сайта: как попасть в цитирование нейросетей (+ пример)
Думаю, вы заметили, что поисковая выдача перестала быть прежней. Если ещё пару лет назад пользователь видел привычный список ссылок, сегодня всё чаще ответ формирует искусственный интеллект. И кому‑то, если не большинству, гораздо проще и быстрее взять ответ на свой запрос из ИИ‑выжимки. Вместо долгого и муторного пути поиска, клика, поиска, сравнения и так по кругу, пока не обойдёшь хотя бы несколько сайтов (сколько хватит терпения и концентрации) — можно подсмотреть 1‑2 компании в ответе без лишних действий.
ChatGPT, Bing Copilot, Perplexity, ЯндексGPT — все они создают готовый ответ на основе источников, которым доверяют.
Для бизнеса, которым классическая оптимизация не обеспечит ТОП (из‑за высокой конкуренции, например) или им мало высоких позиций — есть запрос на бренд — это хорошая возможность, пока инструментом ещё не пользуются все. Ранний старт даёт свои преимущества и с конкурентной точки зрения, и в наращивании доверия у алгоритмов: нейросети обучаются на уже существующих данных и продолжают цитировать знакомые источники.
Мы сами оптимизируем контент сайта под ИИ‑ответ и решили на своём примере разобрать, как же бизнесу влиять на ИИ‑выдачу?
Что сработало — структура, смысл, плотность фактов или подход к объяснению? И главное — какие выводы может сделать бизнес, чтобы его контент тоже попадал в AI‑цитирование? Читаем, внимаем, применяем.
Как AI‑поиск выбирает, какие сайты цитировать
AI‑ассистенты — ChatGPT, Copilot, Perplexity, YandexGPT — не создают контент с нуля. Они пересобирают существующую информацию из открытых источников и формируют на её основе ответ. Поэтому для бизнеса принципиально важно, чтобы сайт оказался среди тех, чьи материалы нейросети считают надёжными, понятными и экспертными. Нейросеть то выдаст ответ, но вот будет он правильным? Заметьте, речь даже не о том, чтобы быть процитированными. Иногда просто нейросеть галлюцинирует данные
Решение одно — сформировать надёжный интернет‑источник самому, а системная работа с классическим SEO вам в помощь. Всё, что раньше было основой поисковой оптимизации, сегодня стало и входным фильтром для AI‑цитирования.
Сайт должен быть технически читаемым. AI‑боты сканируют страницы так же, как поисковики. Если в robots.txt стоят запреты, встречаются ошибки 404, дубли или тяжёлый JavaScript‑контент — система просто не сможет прочитать страницу.
Без доступности на этапе AI Discovery сайт не появится в ответах, даже если материал идеален по смыслу.
Контент — полный, структурный, без воды. Нейросети ищут не отдельные фразы, а самодостаточные фрагменты. Поэтому лучше читаются тексты с чёткой логикой: вопрос → пояснение → пример → резюме.
Развёрнутые материалы, закрывающие интент целиком, получают преимущество перед короткими заметками. Чем плотнее изложение, тем выше шанс, что AI возьмёт цитату без искажений.
Это, если вы понимаете, актуально и для пользователя. А нам всё ещё очень важно его мнение
Семантика должна быть широкой. LLM‑модели ориентируются не только на «главный» запрос, но и на смежные темы. Если в контенте учтены сопутствующие вопросы, словоформы и подинтенты, нейросеть воспринимает страницу как более содержательную по смыслу.
Это то, что в классическом SEO называется кластерной стратегией — объединение нескольких близких тем вокруг одной опорной.
Структура помогает понять текст. H1–H3, списки, таблицы, FAQ‑блоки — всё это подсказывает AI, где начинается и заканчивается мысль. Для модели структурированный документ — это не просто удобство, а сигнал доверия: такие тексты проще интерпретировать и вставлять в готовые ответы без риска ошибок.
Микроразметка и технические сигналы. Schema.org, JSON‑LD, корректные Title и Description позволяют системам точно определить тип контента — статья, продукт, отзыв, инструкция. Размеченные страницы чаще попадают в индексы Bing, Google и Яндекса, а значит, становятся доступными для нейросетей.
Экспертность и подтверждение опыта. LLM‑модели ориентируются на принципы E‑E-A‑T (опыт, экспертность, авторитет, доверие). Авторство, дата публикации, упоминание инструментов, ссылки на источники — всё это усиливает восприятие страницы как достоверной.
Один текст не создаёт экспертность — но серия материалов, внутренняя перелинковка и ссылки из медиа формируют уже устойчивую репутацию домена.
Влияние поведенческих и UX‑факторов. Быстрая загрузка, отсутствие агрессивной рекламы, удобная навигация и логичная структура — всё это влияет не только на пользователей, но и на AI. Тут даже и добавить нечего.
Регистрация в экосистемах данных. Каждая LLM использует свои источники:
- ChatGPT и Copilot — индексы Bing;
- Perplexity — Bing + Google;
- YandexGPT — Яндекс Поиск, Карты и Бизнес.
Поэтому важно, чтобы сайт присутствовал во всех экосистемах: Bing Webmaster Tools, Google Search Console, Яндекс.Вебмастер и Яндекс.Бизнес.
То есть, чтобы бренд появился в генеративных ответах, нужна работа сразу на трёх уровнях:
Однако, теория теорией, но показательнее будет конкретный пример. Для этого мы возьмём нашу статьи «SEO для сайта на WordPress».
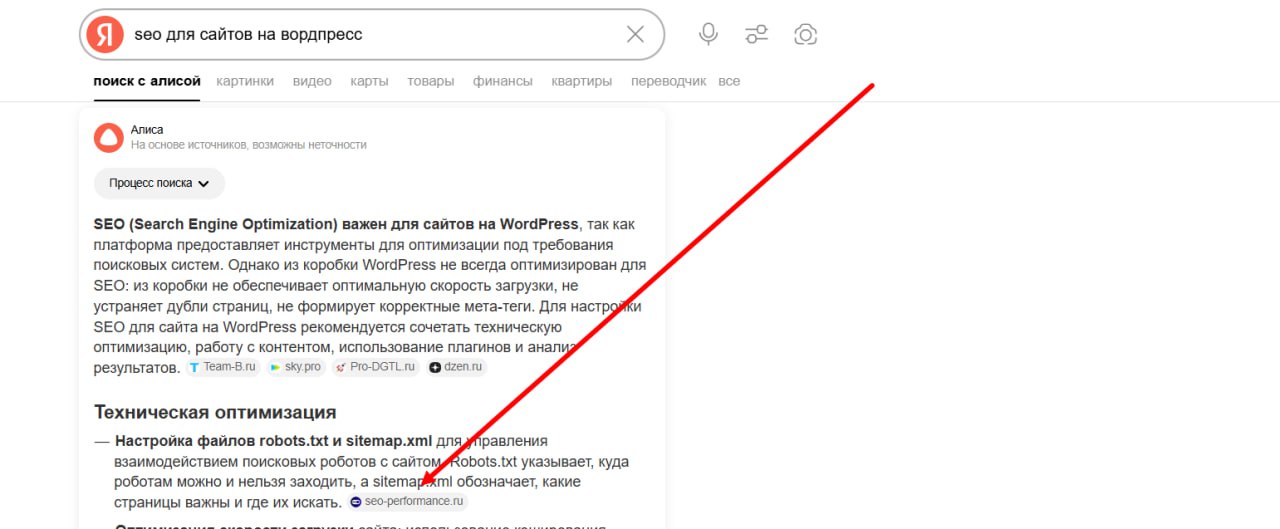
Прежде всего это подробный SEO‑гайд, написанный по всем классическим правилам оптимизации, который предназначался алгоритмам и пользователям (привлечение информационного трафика). И вот путём некоторых манипуляций мы сделали его более понятным и для искусственного интеллекта.

Бесплатная рассылка: как использовать ИИ в бизнесе
Узнайте, как писать эффективные промпты, создавать ИИ‑агентов для решения бизнес‑задач, и проходите мини‑практикумы в популярных сервисах. Всего — семь писем, которые помогут разобраться, как работать с нейросетями
Что делает контент понятным для AI‑поиска (на примере нашего процитированного материала)
На первый взгляд «Подробный гайд по SEO‑оптимизации сайта на WordPress» — это просто большая обучающая статья. Так оно и есть, но ещё материал оказался очень цитируемым почему‑то. Почему?
Структура, логика и язык текста идеально совпадают с тем, как крупные языковые модели понимают информацию — не как человек, через интуицию и контекст, а через закономерности и семантическую завершённость.
Прямая логика и модульность текста. Каждый раздел статьи — автономный блок, отвечающий на конкретный вопрос: «Как выбрать шаблон?», «Как настроить индексацию?», «Как проверить скорость загрузки?».
Такая модульность делает материал “разборным” — AI может извлечь отдельный фрагмент без потери смысла.
На практике это достигается на этапе первичной оптимизации:
- аудите внутренней структуры сайта и логики страниц;
- корректировке заголовков H1–H3 под структуру;
- проработке навигации и sitemap.xml, чтобы модели могли считать материал блоками.
Работа ведётся со структурой и взаимосвязями смыслов, чтобы материал закрывал весь кластер запросов. Модели не цитируют целые тексты — они собирают короткие смысловые куски, где есть чёткая постановка задачи и решение. Именно поэтому в генеративной выдаче чаще оказываются статьи с предсказуемой структурой, а не с повествовательной подачей.
Высокая “смысловая плотность”. В тексте нет лишнего: ни вводных рассуждений, ни обобщающих пассажей. Каждый абзац несёт инструкцию, чек‑лист или измеримый результат:
- «Снимите галочку с пункта “Запретить индексировать сайт”».
- «Добавьте сайт в Яндекс.Вебмастер и укажите главное зеркало».
- «Используйте GZIP‑сжатие и минификацию CSS».
Такой язык AI воспринимает как готовый ответ. Он “понимает”, что это законченная мысль.
Чёткие переходы и иерархия. В статье выстроена логика от базового к частному:сначала — шаблон, затем — структура сайта, потом — индексация, разметка, плагины и метаданные. Для модели такая последовательность выглядит как обучающий сценарий.
Основа тому, кстати, первичная оптимизация и GEO‑подготовка:
- исправление дублей, 404‑ошибок, каноникалей;
- работа с региональностью и семантическими метками;
- использование внутренних ссылок, чтобы AI мог следовать за структурой.
Сигналы достоверности и консистентность. Гайд содержит инструменты, ссылки и примеры: Google Search Console, Яндекс.Вебмастер, Schema.org, PageSpeed Insights. Для AI это маркеры доверия: материал основан на проверяемых источниках, а не чисто личном мнении автора. Особенно, если важные тезисы/слова повторять несколько раз.
На этом этапе подключается оптимизация под генеративные сети:
- внедрение микроразметки FAQ и HowTo;
- публикация выдержек и вспомогательных материалов (кейсы, сравнения, чек‑листы) на внешних площадках;
- трекинг попадания страниц в AI‑блоки и корректировка формулировок по логам.
Язык и тон. В гайде только факты, инструкции и аргументы. Это важно: AI плохо работает с эмоциональной риторикой, но хорошо понимает технически чистый язык. Такая речь одновременно формальна и доступна, что делает материал пригодным для любого — от LLMки до пользователя.
Универсальность подачи. Хотя текст посвящён WordPress, его структура применима к любому CMS‑проекту. AI воспринимает такие статьи как типовые справочники, которые можно использовать в ответах вне контекста конкретного бренда или ниши. Чем универсальнее тексты, тем выше шанс цитирования.
Это обеспечивается на уровне контент‑кластеров: создаётся серия связанных материалов под разные платформы и задачи, объединённых одной структурой и смыслом.
В итоге нейросеть считывает паттерн контента и воспринимает сайт как устойчивый источник по теме. Как это ещё может отражаться на ответах:
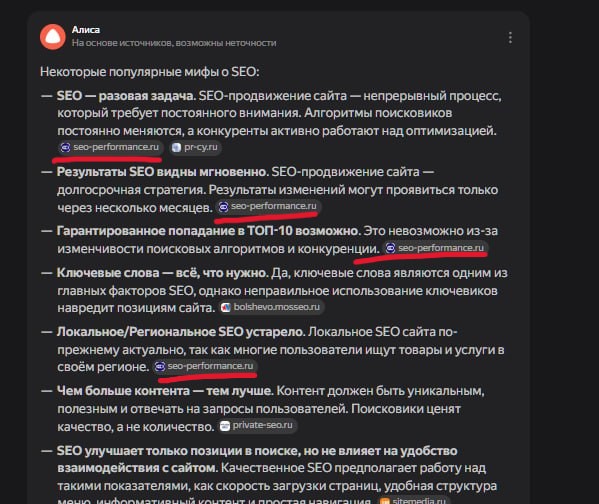
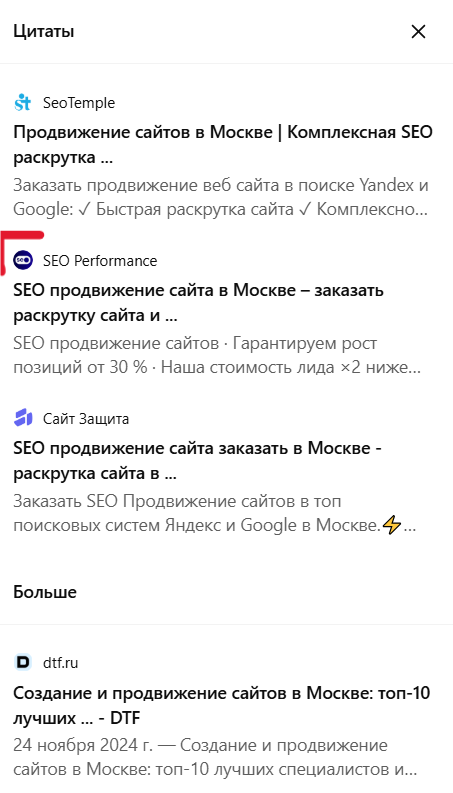
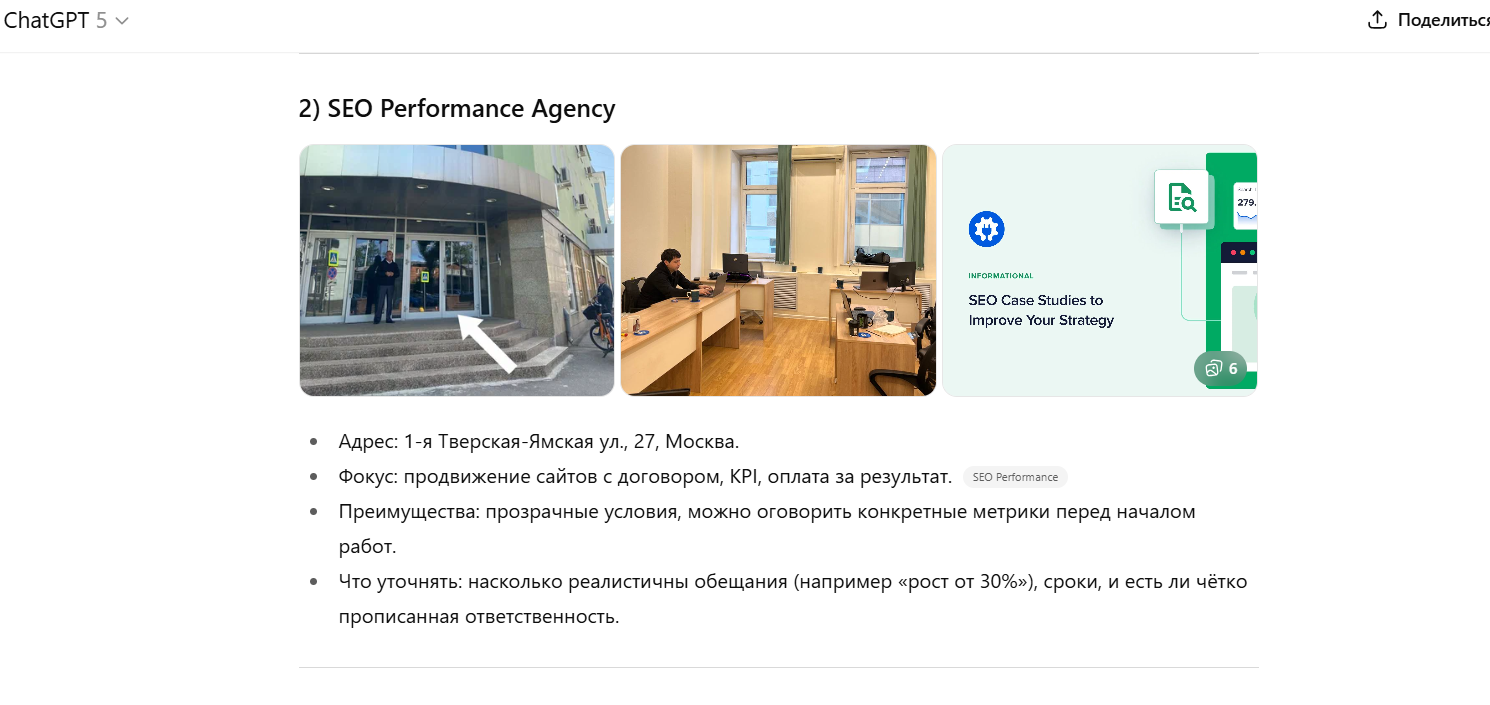
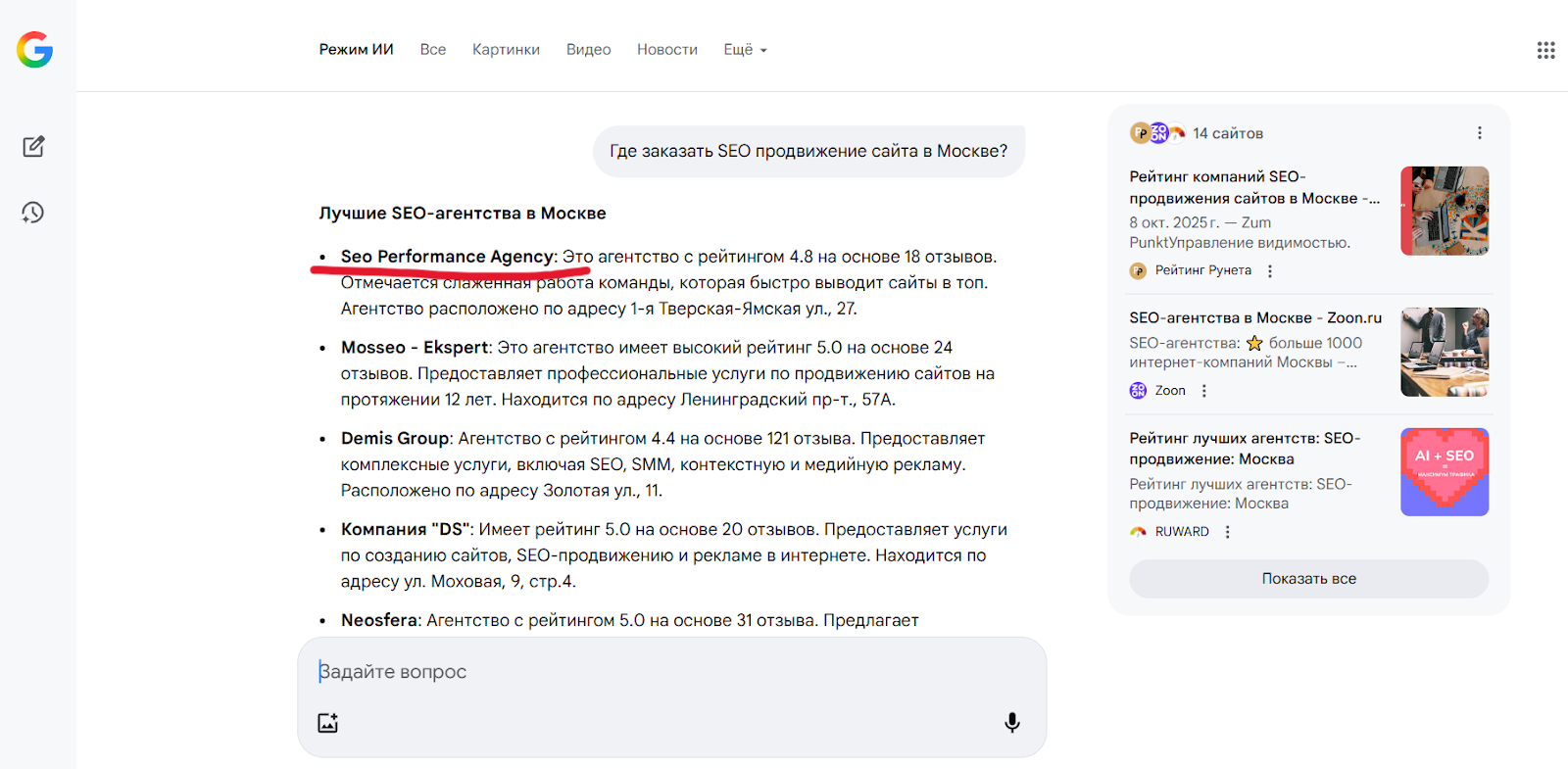
По сути, статья про SEO для WordPress стала цитируемой не потому, что писалась под нейросети, а потому что была выстроена по принципам хорошего обучения: логика, ясность, структура, отсутствие шумов.
Какие форматы контента лучше воспринимаются AI
Если отойти от содержания разобранного материала, остаётся не отмеченным его формат. Так всем будет удобнее: некоторые виды публикаций сами по себе подразумевают чёткую структуру, логику разделов и однонаправленность мысли.
Как я и говорил, ИИ‑ассистенты распознают закономерности, ищут завершённые смысловые блоки и выстраивают из них собственные ответы. Отсюда — закономерность: цитируются не любые тексты, а те, где идея выражена просто, повторяемо и последовательно. Вот мои фавориты в этом плане:
- Гайды и инструкции: пошаговая структура, короткие блоки, чёткие подзаголовки нумерация.
- FAQ и Q&A.
- Аналитические обзоры и сравнения: данные, таблицы и конкретные выводы.
- Кейсы и разборы (структура «задача → процесс → результат → вывод»).
- Статьи с одной смысловой осью (одна тема — одна цель).
- Единый язык и повтор ключевых формулировок.
- Сквозные элементы сайта: футер, меню, карточки, описание компании — должны быть логичны и совпадать по смыслу.
Такой подход делает тексты удобными для алгоритмов, моделей, — а значит, усиливает видимость бренда в генеративной выдаче. Но что же до людей? Им такую подачу нормально будет читать?
Нейросети любят структуру, а люди — смысл: как совместить AI‑оптимизацию и живой стиль
Понимаю, очень тонкая грань. Поэтому главная ошибка, которую сегодня делают компании, услышав об «оптимизации под AI», — начинают писать тексты так, будто их единственная и основная аудитория — алгоритм. Сухо, шаблонно, без контекста и эмоций. С таким противоречием мы сталкивались и в SEO оптимизации.
AI‑дружественный ≠ безжизненный. Важно не подавлять интонацию, а упорядочить смысл.
Эмоции и структура не противоречат. Одно дело, когда мысли и их последовательность путается из‑за эмоционального фона автора и совсем другое, когда вы пишите живо и внутри текста есть:
- логичный ритм (вопрос → ответ → пример → вывод);
- короткие абзацы, где каждая мысль закончена;
- подзаголовки, которые описывают суть, а не настроение и отношение.
Тогда все будут довольны
Стиль — для людей, логика — для машин. AI не обращает внимание на харизму текста, но улавливает нарушение связи. Поэтому можно оставлять авторскую подачу, метафоры, даже лёгкую иронию — если смысл при этом сохраняет ясную структуру.
Например, фраза “Неверно выбранный шаблон WordPress — как двигатель в спорткаре, собранный из подручных деталей” для модели считывается как пример внутри раздела о технических ошибках, а для человека — как образ, который запоминается. Это идеальный баланс: смысл + выразительность.
AI‑дружественный = дисциплинированный. В основе AEO/GEO не запрет на легкость и живость, а управляемость текста: чтобы каждая мысль имела границы, повторялась в нужных местах, а не терялась в тексте.
Системность усиливает личность. Когда бренд регулярно публикует материалы с единым языком, последовательной логикой и узнаваемым стилем, AI начинает воспринимать его как цельный источник. И чем выше согласованность формулировок и тональности, тем сильнее бренд выглядит и для человека, и для нейросети.
Итог: не нужно писать сухо, нужно писать ясно, логично и по‑человечески — такой язык общий для всех.
Подытожим: признаки контента, который цитирует AI
После анализа становится очевидно: тексты, которые цитируют нейросети, объединяет не тематика и не длина, а структура и смысл. Они построены одинаково логично — независимо от ниши или стиля бренда.
Главные признаки таких материалов:
И будет вам счастье!
Как проверить, цитирует ли ваш контент AI
Проверка по системам. Bing — база для ChatGPT, Copilot и Perplexity:
- Добавьте сайт в Bing Webmaster Tools, проверьте карту сайта, индексацию, ошибки и структуру.
- Если вас нет в индексе Bing, шансы попасть в ChatGPT‑ответы минимальны.
Google — источник для Gemini (бывший Bard) и частично для Perplexity:
- Проверьте Search Console, статус страниц, корректность Schema.org и скорость.
- Введите запросы по теме в Gemini и посмотрите, какие сайты он цитирует. (Тут можно и за конкурентами подсмотреть — на момент того, что есть у них и нет у вас).
Яндекс — база для YandexGPT:
- Убедитесь, что сайт зарегистрирован в Яндекс.Вебмастере, карточка компании оформлена в Яндекс.Бизнесе, а описания и отзывы совпадают с текстами на сайте.
- Проверьте, как ЯндексGPT отвечает на вопросы о вашей нише — появляются ли в ответах ваши формулировки, данные, описание услуг.
Perplexity / Claude / ChatGPT — гибридные модели:
- Perplexity показывает источники прямо под ответом — это самый наглядный способ увидеть, где вы стоите.
- В ChatGPT можно запросить “Источник информации для [запрос]”.
- Claude (Anthropic) использует смесь Bing и собственного индекса — если вы есть в Bing, но не цитируетесь в Claude, вероятно, не хватает внешних упоминаний.
Проведите ручной тест. Введите запросы по вашим темам: «SEO для сайта на WordPress», сравните, какие сайты попадают в ответы разных систем. Если среди них ваших нет, изучите структуру цитируемых материалов — почти всегда они длиннее, логичнее и шире по охвату темы.
Проверьте техническую доступность. Даже идеальный контент не попадёт в выдачу, если AI‑боты не могут его прочитать:
- Проверьте файл robots.txt, чтобы не было блокировок для ChatGPT‑User, Bingbot, YandexBot, PerplexityBot, Googlebot.
- Используйте валидаторы (technicalseo.com/tools/robots‑txt, schema.org/validator) для диагностики.
Узнайте, как AI “видит” ваш бренд. Задайте нейросетям прямые вопросы:
- “Что такое [название компании]?”
- “Кто оказывает услуги [ниша] в России?”
- “Кто делает [ваш продукт]?”
- и т.д.
Если ответ не отражает реальность, значит, у вас разорвана смысловая сеть: AI берёт данные из сторонних источников, старых описаний или у более подготовленных конкурентов.
Отслеживайте динамику. Раз в месяц повторяйте проверку: AI‑ответы обновляются быстрее поисковых индексов. Важно не просто попасть, а закрепиться как надёжный источник — для этого контент должен регулярно обновляться, а структура оставаться стабильной.
Заключение: контент, понятный людям и AI‑поиску
Попадание в AI‑выдачу — это не для всех. Потому что:
- не разово, а результат системной, выверенной работы;
- не для мгновенного эффекта (как реклама за клики);
- не подойдёт для основного канала продаж, поскольку выстраивает бренд и узнаваемость.
Это не ещё одно направление SEO, а новый слой видимости и новая реальность под которую придётся подстроится и клиентам (бизнесу), и подрядчикам (сеошникам) — просто кто‑то сделает это как всегда быстрее, став лидером.
Про контент повторюсь кратко: он должен быть способен объяснить, обучить и подтвердить опыт, чтобы как надо воздействовать и на людей, и на алгоритмы. Как итог: укрепление доверия, масштабирование экспертизы и место в ИИ‑ответе.














