

Скучный ИИ как рутинный инструмент оптимизации
Но что делать, если у вас нет тысяч видеокарт, штата ML‑инженеров и бюджета на дообучение крупных языковых моделей? Предлагаем взвешенный подход к перспективной технологии — именно так мы подходим к этому в Ensi Cloud.
Стратегия “Скучный ИИ”
Невероятный хайп вокруг ИИ мешает рассчитать реальную рентабельность его внедрения в каждом конкретном случае. Мы сформулировали принципы под общим названием «Скучный ИИ», которые помогают принимать бизнес‑решения без оглядки на медийное давление:
- На рынке нет кейсов комплексной эффективности ИИ. Есть только локальные решения, которые оптимизируют процессы, но не меняют бизнес целиком.
- ИИ — широкое понятие. Хайп последних лет на самом деле связан с Machine Learning — одним из направлений ИИ. Использование термина «машинное обучение» помогает избежать ловушек хайпа.
- Машинное обучение — не новое изобретение. Этот метод активно используется уже лет 20. Например, Яндекс Алисе уже 8 лет.
- Комплексные ML‑решения не дают абсолютной эффективности. У всех был опыт общения с чат‑ботами, когда приходилось звать оператора. Оставлять клиента наедине с ML‑решением — риск потерять его лояльность, и об этих рисках нужно помнить.
- ML‑решения дороги. Это касается и операционных затрат (подписки, токены, ресурсы на собственные модели), и капитальных (сбор данных, обучение). Часто они дороже традиционных алгоритмов или человеческого труда.
- Для ML нужны качественные данные. У многих компаний данных либо мало, либо они загрязнены, либо и то, и другое.

Бесплатная рассылка: как использовать ИИ в бизнесе
Узнайте, как писать эффективные промпты, создавать ИИ‑агентов для решения бизнес‑задач, и проходите мини‑практикумы в популярных сервисах. Всего — семь писем, которые помогут разобраться, как работать с нейросетями
Принцип № 1. Специализация, а не генерализация
Подход «Скучный ИИ» десакрализирует искусственный интеллект и предлагает относиться к нему как к узкоспециализированному инструменту, который полезен в определённых случаях. Вместо создания сложных ML‑систем, которые пытаются целиком заменить человека в решении масштабных задач (что чаще всего под силу лишь мировым гигантам), для большинства компаний эффективнее применять машинное обучение точечно. Ведь это просто один из многих инструментов.
Например, не строить решение, которое полностью заменит команду поддержки, а дать сотрудникам ИИ‑помощника для быстрого подбора товаров по запросу клиента. Это управляемое с точки зрения затрат решение, эффективность которого легко проверить.
И важно помнить: это лишь часть поддержки — множество других задач по‑прежнему решаются без какого‑либо ИИ. В конечном счёте, успех всей затеи определяет не технология, а качество проработки задачи: глубокая аналитика и чёткое понимание, что на самом деле нужно клиенту.
В бизнесе среднего размера не так уж и много задач, где выявление паттернов в данных и генерации на их основе нового контента (супер способность ML‑технологий) будет иметь явный экономический эффект. Как правило, это точечные задачи по повышению производительности или устранению неэффективности в рамках конкретного процесса. К тому же есть одно существенное требование — безупречное качество данных. Принцип «Garbage in — garbage out» здесь работает без исключений. В этом месте можно вспомнить об основной задаче IT в современном бизнесе:
- улучшать существующие бизнес‑процессы с помощью IT;
- способствовать созданию новых бизнес‑процессов с помощью IT.
На дворе ИИ‑революция, но фундаментальная задача IT все та же: выявить процессы, которые можно улучшить или создать с нуля, и затем автоматизировать их, используя подходящие инструменты — в том числе, основанные на машинном обучении.
Принцип № 2. Каскад моделей вместо единой универсальной мегамодели
Принцип специализации относится и к архитектуре ML‑решений: вместо создания одной сложной модели, которая пытается решить задачу целиком, эффективнее разбить эту задачу на подзадачи, решать которые будут отдельные модели. В рамках микропродуктового подхода это означает сознательный отказ от больших универсальных моделей (например, от ChatGPT) в качестве фундамента. Они отлично работают, но есть несколько сложностей:
- каждый запрос стоит денег;
- масштабирование требует ресурсов;
- результат всё равно нужно адаптировать под узкий контекст;
- возникают неуправляемые риски безопасности и отказоустойчивости.
Но этот принцип предлагает идти дальше: вместо одной модели (даже если она развёрнута локально) решать задачу с помощью последовательной цепочки — каскада — специализированных моделей.
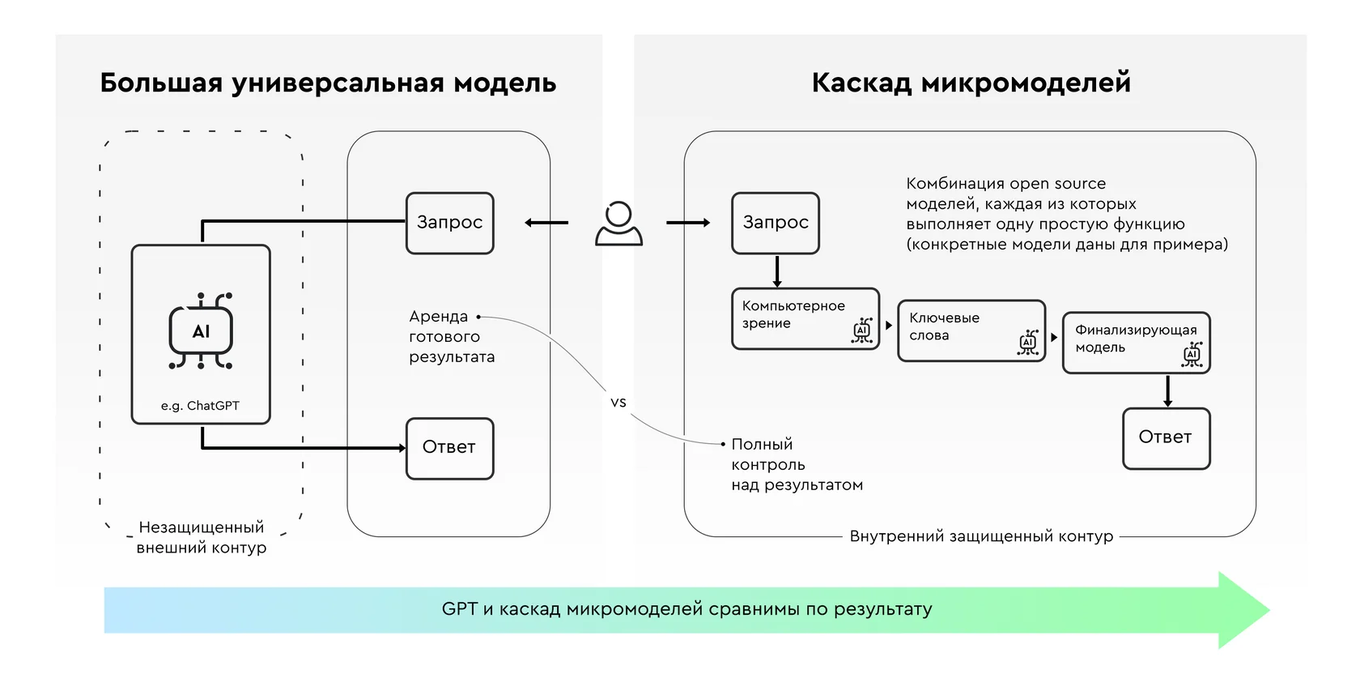
Например, мы в продукте который создает описания и характеристики товаров по фото используем такую цепочку моделей:
- модель машинного зрения — выделяет теги: «диван», «красный», «кожаный»;
- текстовая модель — на основе фото + тегов генерирует черновик описания;
- summarization‑модель — превращает черновик в человекочитаемый текст.
Итог: результат сравним с GPT, но стоимость и задержки — на порядки ниже.
Принцип № 3. Инфраструктура с умным распределением ресурсов
Как известно, ИИ‑решения очень ресурсоемки. В этом нет ничего удивительного, потому что чем ближе интерфейс к человеку, тем больше ресурсов потребляется. Если проследить эволюцию взаимодействия с машиной — машинный код → компилируемые языки → интерпретируемые языки → ML‑модели — то окажется, что атомарная операция на каждом новом уровне требует в тысячи и миллионы раз больше вычислительных ресурсов, чем на предыдущем.
Этот факт еще раз подтверждает, что ИИ следует применять точечно — только там, где его эффективность можно измерить. Но даже для таких задач ресурсы нужно распределять аккуратно. Для этого решаемые задачи и подходящие для них модели логично разделить на три группы в зависимости от требований к производительности и срочности:
- Легкие. Для задач, выполняемых в реальном времени, важно подобрать модели с низкими требованиями к вычислительным ресурсам. Они работают постоянно на выкупленных у провайдера мощностях.
- Средние. Для задач, которые можно выполнять по расписанию, допустимо использовать более ресурсоёмкие модели и запускать их в окна наименьшей нагрузки на той же инфраструктуре, что и легкие модели.
- Тяжёлые — запускаются только вручную и на отдельных гораздо более дешевых прерываемых spot‑инстансах, когда планируется дообучение и другие доработки.
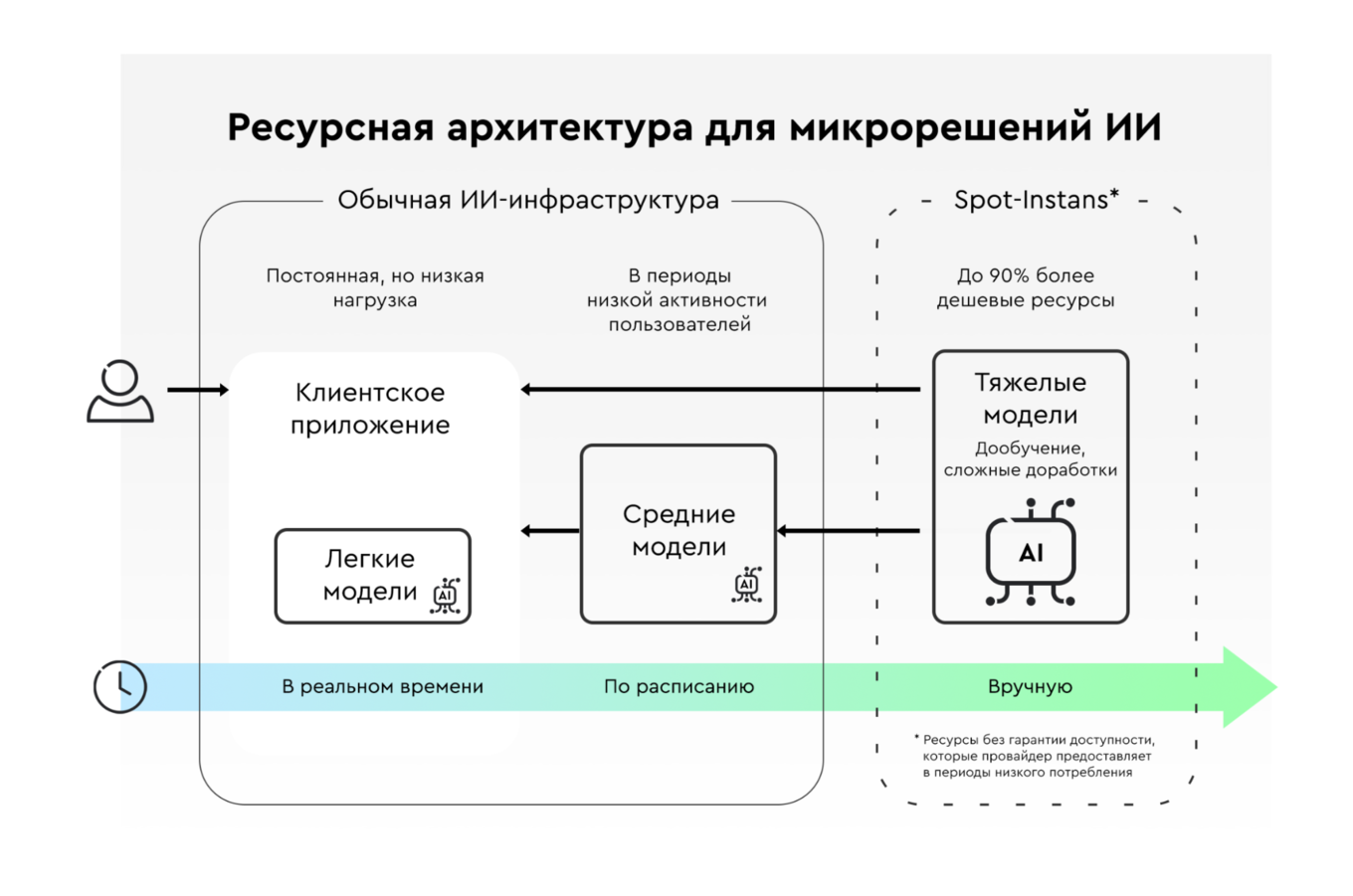
Такое ранжирование позволяет заметно сократить затраты на инфраструктуру, но требует проявлять изобретательность, а также заниматься оптимизацией и дообогащением контекста.
Принцип № 4. Фокус на Clean Data вместо Big Data
Big Data — очередной «волшебный» термин, обещающий чудеса. Все говорят, что данные — это новая нефть. Но у большинства компаний данных не так много, чтобы называть их «большими». И что важнее — сами по себе они прибыли не приносят. Вместо гонки за Big Data стоит сосредоточиться на Clean Data.
Небольшой, но качественный, чистый и релевантный датасет принесёт куда больше пользы, чем огромный и грязный
IT‑ориентированная компания как правило уже имеет чистые датасеты: это может быть товарный фид, история заказов клиентов, маршруты доставок. При этом не обязательно использовать эти датасеты напрямую. Идея каскада моделей предполагает, что в начале более легковесная модель может перерабатывать сырые данные и генерировать новые датасеты, которые станут базой для обучения основной модели.
Если загрузить интерьерное фото дивана в ChatGPT, он сразу выделит главный объект, что это такое и для чего он нужен. Но того же эффекта можно добиться, если сначала гораздо более легкая модель компьютерного зрения сегментирует объекты на изображении, а главная модель анализирует уже эти готовые сегменты. Использование синтетических данных тоже может помочь, но об этом поговорим дальше.
Принцип № 5. Автоматическое обучение на соответствие бизнес‑критериям вместо синтетических тестов
Стандартные тесты и метрики (accuracy, F1 и т. д.) оценивают общую эрудицию модели, но не её эффективность для вашей конкретной задачи. Клиенту всё равно, как ИИ справился с цитатами Шекспира. Его волнует, почему в вашем интернет‑магазине модель отнесла платье к разделу «Обувь».
95% точности в классификации — звучит отлично, но если модель путает детскую и взрослую одежду, то это критическая ошибка.
Для оценки качества ответов ИИ‑микрорешения важно сформулировать бизнес‑критерии, например, для генератора описаний товаров по фото одежды бизнес‑критерии таковы:
- «описание должно содержать: материал, сезон, назначение»;
- «классификация не должна путать категории верхней и нижней одежды»;
- «синонимы должны быть стилистически нейтральными и подходить для карточки товара».
Первоначальные критерии определяют эксперты. Но чтобы выявить типичные ошибки и спорные моменты полезно организовать быстрый сбор фидбека. Для этого вполне подойдут собственные сотрудники или группа лояльных клиентов. Можно, например, создать простой бот в Telegram, где сотрудники могут «поиграться» с моделью, оценить результаты работы и дать обратную связь. Конечно, это не замена массовой разметки данных живыми людьми, зато почти бесплатно и помогает быстро сформулировать важные бизнесу критерии.
После того, как бизнес‑критерии сформулированы, можно запускать автоматическое тестирование в формате LLM‑as‑a-Judge:
- развернуть open source LLM, (например, Qwen);
- написать промпт‑тест на базе сформулированных бизнес‑критериев;
- запустить релевантное обучение без участия человека.
Итого
Искусственный интеллект в виде ML — это космос и новый тип инструмента автоматизации. Но стоит подходить к работе с ним трезво и не забывать контролировать экономическую эффективность решений на базе ML. При этом не нужно быть мегакорпорацией с миллиардными бюджетами. С помощью подхода, описанного в этой статье, и определенной изобретательности можно создавать эффективные ИИ‑микрорешения для оптимизации вашего бизнеса.














